作者:微信小助手
发布时间:2023-10-23T09:51:40
之前,我们已经分享了一些关于实战方面的内容,有一些读者有给我留言,说这些内容对日常工作有帮助,这让我感到非常开心。
所以,今天我们继续来讲讲实战方面的内容,那就是:如何定位java程序中的性能问题?
你也许是这样来定位问题的
有一个接口提供服务,但这个服务现在耗时很长,无法满足我们的要求,我们需要找到其中的性能问题并解决。
说白了,就是程序比较慢,我们要找到慢的地方。
最常见的办法无非是在代码各处添加打点逻辑,统计每一块代码的运行时间,类似下图这样:
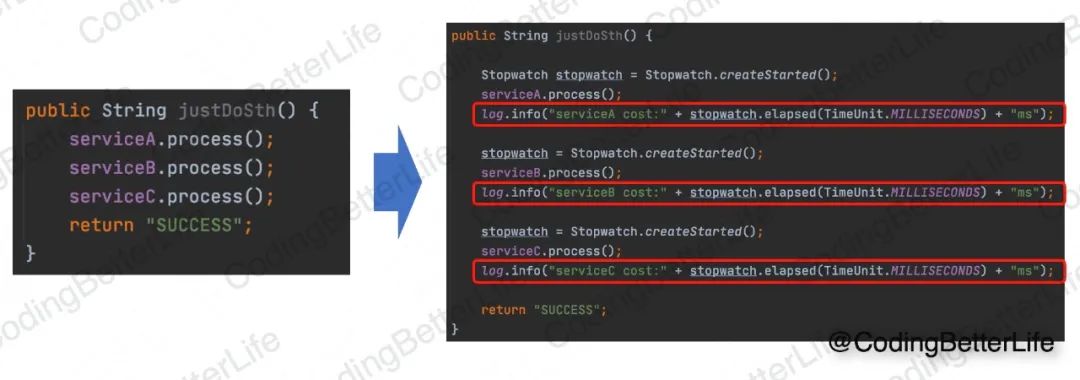
这种办法有几个问题:
【1】打点的地方太多了,导致代码特别乱。
【2】容易漏了打点,导致关键位置没有分析到。
【3】很多时候会在线下环境打点分析,但是线下又没有足够的请求来复现性能问题。
【4】不是所有请求都会有性能问题,但打点针对所有请求,导致打点数据太多无法分析。
相信这些点很多同学都感同身受。一个性能分析花上几周都不见得能够定位到问题,更别谈解决了。
今天我给大家来介绍下如何使用Arthas来定位代码中的性能问题。也许无法解决所有问题,但“病急乱投医”的你用一下,搞不好就“瞎猫碰到死耗子了呗”

我这种说法好像是碰碰运气,但事实上在绝大部分场景下,Arthas可以帮助到我们的。我们这就开始吧。
01
Arthas是什么
用Arthas之前,我们还是要先介绍一下它。
Arthas是阿里巴巴开源的Java诊断工具,能够在线诊断Java应用程序的性能问题。它可以实时查看应用的线程、类、对象、方法等信息,并且支持热更新类和方法,还可以执行JVM命令和监控系统指标。此外,它还支持Spring Cloud应用、Dubbo服务等场景的诊断与治理,非常适合Java开发及运维人员进行Java应用程序的线上问题排查和性能优化。
我们看下其中的关键字:开源、Java、性能问题、热更新、JVM监控、线上问题排查。
看到这些关键字,相信我已经不用做过多的介绍,你已经可以对Arthas的功能知道个八九不离十了。
我还是来再枚举下Arthas的功能:
【1】实时查看应用的线程、类、对象、方法等信息,支持热更新类和方法。同类工具参考:JConsole、VisualVM、YourKit。
【2】执行JVM命令,监控系统指标,如堆内存、GC、线程等。同类工具参考:jcmd、jstack、jmap等。
【3】支持Spring Cloud应用、Dubbo服务等场景的诊断和治理。同类工具参考:SkyWalking、Pinpoint、Zipkin等。
【4】实时监控请求的响应时间,打印出耗时最长的方法调用链。同类工具参考:Spring Boot Actuator、Micrometer等。
【5】追踪和分析方法的入参和返回值,支持 MVEL 等方式的表达式。同类工具参考:AspectJ、logback。
02
如何使用Arthas诊断代码性能问题
基础诊断
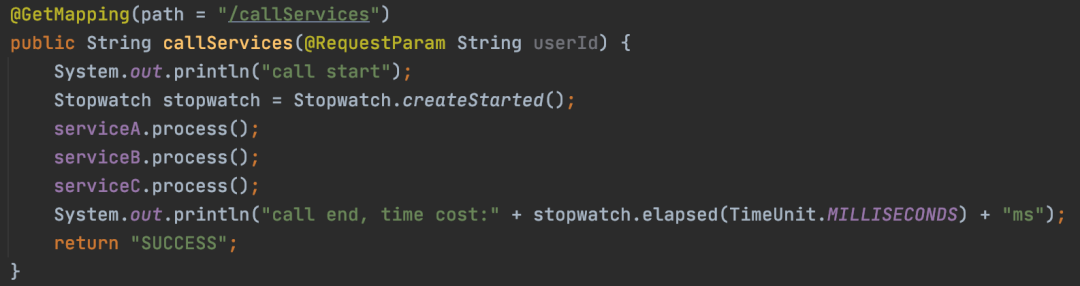
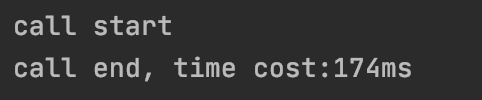
最常规的办法就是上面提到的加上各种打点,我们再图示一下这种方式,如下:
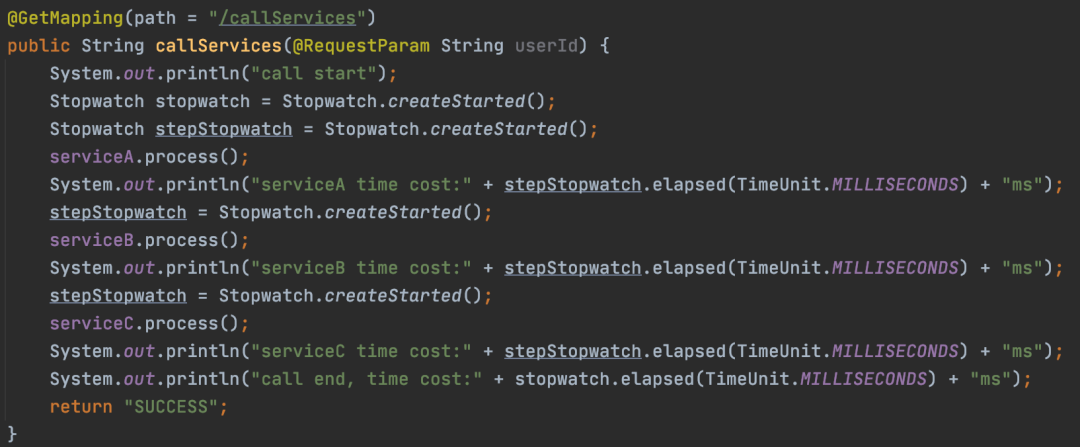
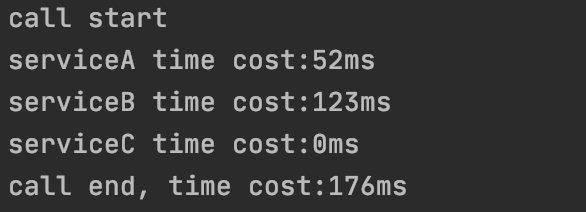
可想而知,如果代码很多,其中的方法又层层嵌套的话,不知道要加多少打点代码了。
如果用Arthas的话,我们可以用它的trace命令来直接查看各个方法的耗时,我们一步步来做一下(这里我们省略了arthas的安装过程,非常容易):
【step1】启动我们的应用
第一步当然是先启动应用。
【step2】使用Arthas连接到我们的JVM进程
我们到arthas所在目录下,执行如下命令:
java -jar arthas-boot.jar我们可以看到如下结果:

我们可以从中看到本地运行的所有jvm进程,从其中选择我们的程序【2】,输入2回车即可。
我们就进入了还蛮有腔调的Arthas工作台。
【step3】使用trace命令指定追踪的类和方法
接着我们输入要追踪的类和方法。输入格式为:trace {全限定类名} {方法名}:

【step4】定位耗时部分
我们来访问下controller中的callServices这个方法。这个时候arthas控制台有如下输出:
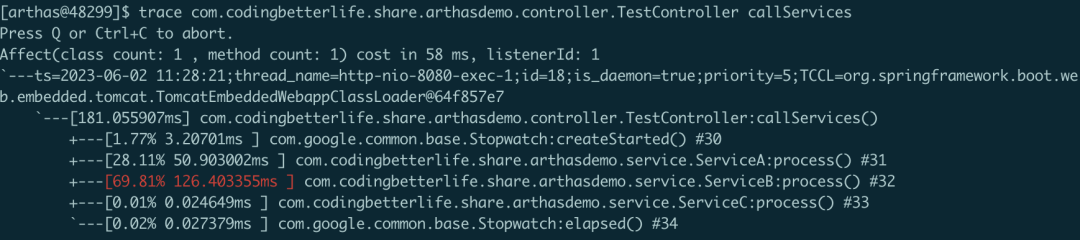
我们可以看到,arthas给我们分析了整个过程中最耗时的部分。这不就是我们想要的功能吗?我们可以选择其中耗时的部分继续往下排查。
怎么往下?重新trace耗时的类名+方法名就好了。

就这样,我们找到了这个demo中耗时的部分,就是RpcC这个远程调用耗时过长。
进阶诊断
但在真实世界中,诊断可能没有那么简单,最常见的现象就是:并不是所有的请求都有性能问题,而往往是其中的一部分请求表现出了性能问题。
在Arthas中,可以对需要观测的请求做筛选,以使得我们观测到我们关心的部分。
【根据入参筛选】
最常见的筛选条件就是根据入参进行筛选:

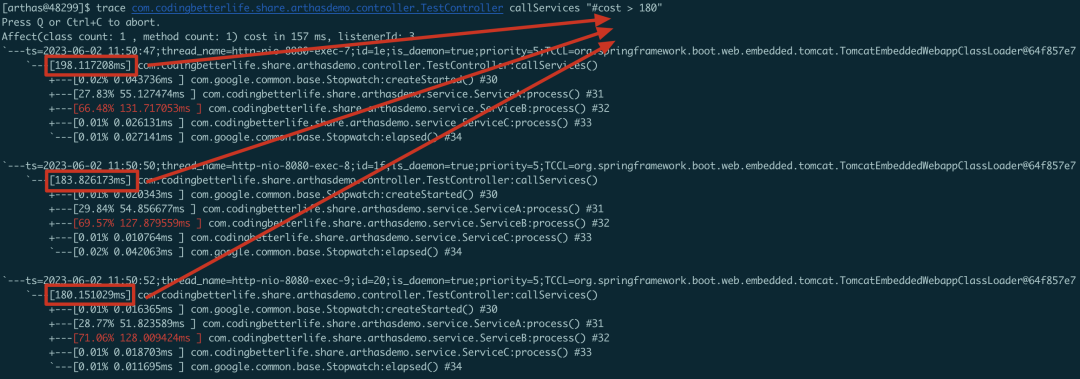
【根据耗时筛选】
还有一种较为常见的,就是我们只关心达到一定运行时间的情况,比如某个方法超过180ms我才关心其具体情况。那我们就可以使用#cost关键字。例如:
03
火焰图
最后,我们再来聊聊在碰到性能问题时我们常用到的一个工具,那就是“火焰图”。
火焰图并不是Arthas发明出来的东西,而Arthas中可以方便的采样并生成火焰图。我们来看一个例子(这个例子是上面我们讲述Arthas定位性能问题时用到的例子,这里再重新看一下 ):
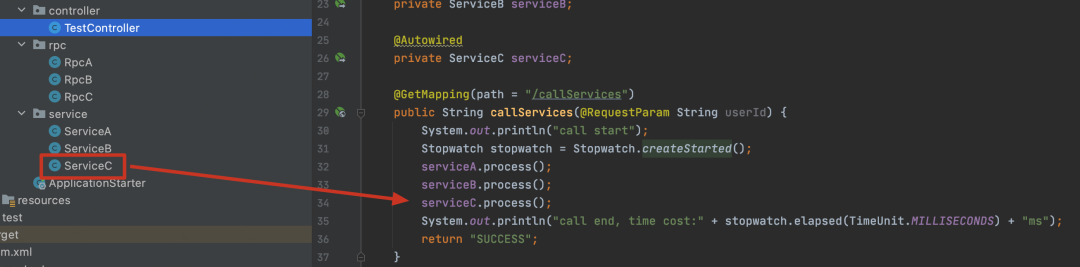
从例子中可以看到,callServices接口调用了三个服务(ServiceA、ServiceB、ServiceC)。
然后,我们在Arthas中依次开启profile采集、观察采集样本数、终止采集(这里需要注意的是,profiler start默认对cpu采样,你也可以选择采样事件):

然后,我们打开采样后的火焰图(火焰图地址会在profiler stop后显示在终端)
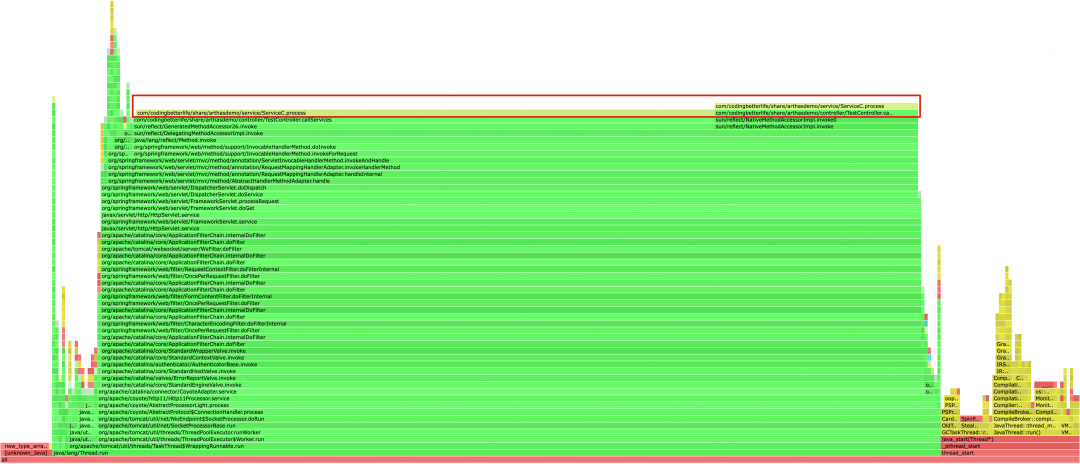
简单说下火焰图怎么看:
【纵轴(Y轴)】表示的是方法调用的调用栈信息,即从最外层方法到最内层方法的调用信息。
【横轴(X轴)】表示的是方法调用的持续时间,即方法在执行过程中所占用的时间长度。
在一个火焰图中,越靠近下面的函数在x轴上越长是正常的,而越往上的函数就应该越短。所以,火焰图也像是一个个山峰。那么,如果火焰图出现较宽的峰顶,那就往往是性能瓶颈。
如上图所示,出现了明显的“平顶”。“平顶”对应的函数是ServiceC.process函数,我们看一下他的实现。
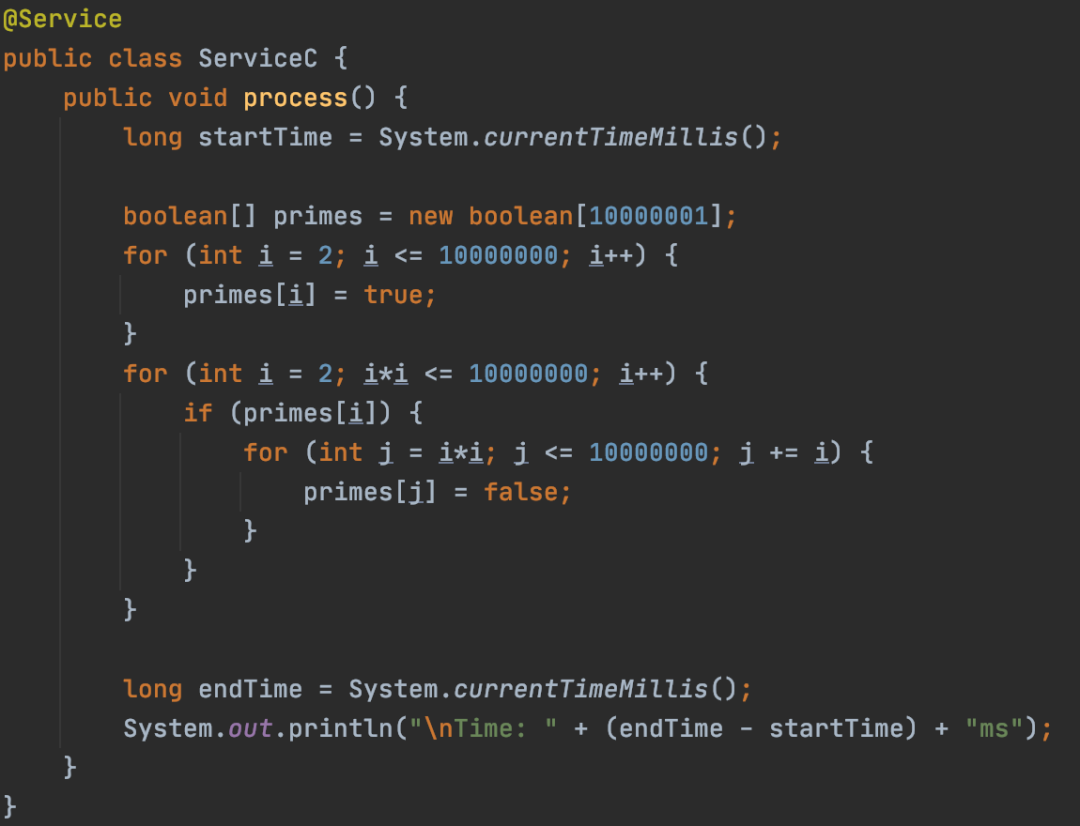
没错,这个ServiceC正是我故意实现的一个较为耗时的函数(计算1000w内的所有质数)。
所以,通过火焰图,我们找到了性能问题。
结语
到这里,我们把【如何使用Arthas定位java性能问题】讲完了。
事实上,Arthas远比今天介绍的要强大和丰富。这篇文章也算是Arthas的敲门砖,如果你感兴趣,非常推荐你自己去研究研究(Arthas的阿里云官网)。
回头说,性能问题是一个范围很广的问题。语言层面、算法层面、通信层面、部署层面等等都会有性能问题及对应的解决方式。我们今天仅聚焦在其中的一个小点,也就是定位java程序内的性能瓶颈。但我相信,这个点往往是我们工作中最常碰到和死磕的点。
希望今天的内容能够帮助到你,也推荐你收藏,如果以后碰到可以拿出来用用。
最后想要再叨叨两句我的【实战板块】。我对【实战板块】的要求是“小而美”。
所谓的【小】是指具备可操作性。你有某方面的问题,这篇文章足够帮助你动起手来就可以,并不追求多么全面。
所谓的【美】是指具备实用性。实战板块的内容就是针对日常工作的,不追求高大上的各种概念,接地气。
最后欢迎大家加入苏三的知识星球【Java突击队】,一起学习。
星球中有很多独家的干货内容,比如:Java后端学习路线,分享实战项目,源码分析,百万级系统设计,系统上线的一些坑,MQ专题,真实面试题,每天都会回答大家提出的问题,免费修改简历,免费回答工作中的问题。
星球目前开通了9个优质专栏:技术选型、系统设计、踩坑分享、工作实战、底层原理、Spring源码解读、痛点问题、高频面试题 和 性能优化。
加入星球如果不满意,3天内包退。

