作者:演戏
发布时间:2015-09-08T10:04:09
Mycat 是什么?从定义和分类来看,它是一个开源的分布式数据库系统,是一个实现了 MySQL 协议的 的 Server,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以 用 MySQL 原生(Native)协议与多个 MySQL 服务器通信,也可以用 JDBC 协议与大多数主流数据库服务器通 信,其核心功能是分表分库,即将一个大表水平分割为 N 个小表,存储在后端 MySQL 服务器里或者其他数 据库里。 Mycat 发展到目前的版本, 已经不是一个单纯的 MySQL 代理了, 它的后端可以支持 MySQL、 SQL Server、 Oracle、DB2、PostgreSQL 等主流数据库,也支持 MongoDB 这种新型 NoSQL 方式的存储,未来还会支持更多 类型的存储。而在最终用户看来,无论是那种存储方式,在 Mycat 里,都是一个传统的数据库表,支持标 准的 SQL 语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度, 在测试阶段,可以将一个表定义为任何一种 Mycat 支持的存储方式,比如 MySQL 的 MyASIM 表、内存表、 或者 MongoDB、 LevelDB 以及号称是世界上最快的内存数据库 MemSQL 上。 试想一下, 用户表存放在 MemSQL 上,大量读频率远超过写频率的数据如订单的快照数据存放于 InnoDB 中,一些日志数据存放于 MongoDB 中,而且还能把 Oracle 的表跟 MySQL 的表做关联查询,你是否有一种不能呼吸的感觉?而未来,还能通过 Mycat 自动将一些计算分析后的数据灌入到 Hadoop 中,并能用 Mycat+Storm/Spark Stream 引擎做大规模数 据分析,看到这里,你大概明白了,Mycat 是什么?Mycat 就是 BigSQL,Big Data On SQL Database。 对于 DBA 来说,可以这么理解 Mycat: Mycat 就是 MySQL Server, 而 Mycat 后面连接的 MySQL Server, 就好象是 MySQL 的存储引擎,如 InnoDB, MyISAM 等,因此,Mycat 本身并不存储数据,数据是在后端的 MySQL 上存储的,因此数据可靠性以及事务 等都是 MySQL 保证的, 简单的说, Mycat 就是 MySQL 最佳伴侣, 它在一定程度上让 MySQL 拥有了能跟 Oracle PK 的能力。 对于软件工程师来说,可以这么理解 Mycat: Mycat 就是一个近似等于 MySQL 的数据库服务器,你可以用连接 MySQL 的方式去连接 Mycat(除了端 口不同,默认的 Mycat 端口是 8066 而非 MySQL 的 3306,因此需要在连接字符串上增加端口信息) ,大多数 情况下,可以用你熟悉的对象映射框架使用 Mycat,但建议对于分片表,尽量使用基础的 SQL 语句,因为这 样能达到最佳性能,特别是几千万甚至几百亿条记录的情况下。 对于架构师来说,可以这么理解 Mycat: 31 Mycat 是一个强大的数据库中间件,不仅仅可以用作读写分离、以及分表分库、容灾备份,而且可以用 于多租户应用开发、云平台基础设施、让你的架构具备很强的适应性和灵活性,借助于即将发布的 Mycat 智能优化模块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,你可以自动或手工调整后 端存储,将不同的表映射到不同存储引擎上,而整个应用的代码一行也不用改变。 当前是个大数据的时代,但究竟怎样规模的数据适合数据库系统呢?对此,国外有一个数据库领域的 权威人士说了一个结论:千亿以下的数据规模仍然是数据库领域的专长,而 Hadoop 等这种系统,更适合的 是千亿以上的规模。所以,Mycat 适合 1000 亿条以下的单表规模,如果你的数据超过了这个规模,请投靠 Mycat Plus 吧!
## MYCAT 原理
Mycat 的原理并不复杂,复杂的是代码,如果代码也不复杂,那么早就成为一个传说了。Mycat 的原理
中最重要的一个动词是 “拦截” , 它拦截了用户发送过来的 SQL 语句, 首先对 SQL 语句做了一些特定的分析:
如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库,并将返回的
结果做适当的处理,最终再返回给用户。
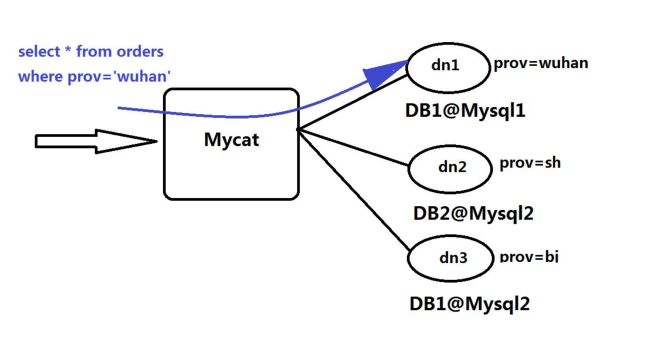 上述图片里,Orders 表被分为三个分片 datanode(简称 dn),这三个分片是分布在两台 MySQL Server
上(DataHost),即 datanode=database@datahost 方式,因此你可以用一台到 N 台服务器来分片,分片规则为
(sharding rule)典型的字符串枚举分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule
function),这里的分片字段为 prov 而分片函数为字符串枚举方式。
当 Mycat 收到一个 SQL 时, 会先解析这个 SQL, 查找涉及到的表, 然后看此表的定义, 如果有分片规则,
则获取到 SQL 里分片字段的值,并匹配分片函数,得到该 SQL 对应的分片列表,然后将 SQL 发往这些分片
去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端。以 select * from Orders where prov=?
语句为例,查到 prov=wuhan,按照分片函数,wuhan 返回 dn1,于是 SQL 就发给了 MySQL1,去取 DB1 上
的查询结果,并返回给用户。
如果上述 SQL 改为 select * from Orders where prov in ( ‘wuhan’ , ‘beijing’ ), 那么, SQL 就会发给 MySQL1
与 MySQL2 去执行,然后结果集合并后输出给用户。但通常业务中我们的 SQL 会有 Order By 以及 Limit 翻页
语法,此时就涉及到结果集在 Mycat 端的二次处理,这部分的代码也比较复杂,而最复杂的则属两个表的
Jion 问题,为此,Mycat 提出了创新性的 ER 分片、全局表、HBT(Human Brain Tech)人工智能的 Catlet、以
及结合 Storm/Spark 引擎等十八般武艺的解决办法,从而成为目前业界最强大的方案,这就是开源的力量!
上述图片里,Orders 表被分为三个分片 datanode(简称 dn),这三个分片是分布在两台 MySQL Server
上(DataHost),即 datanode=database@datahost 方式,因此你可以用一台到 N 台服务器来分片,分片规则为
(sharding rule)典型的字符串枚举分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule
function),这里的分片字段为 prov 而分片函数为字符串枚举方式。
当 Mycat 收到一个 SQL 时, 会先解析这个 SQL, 查找涉及到的表, 然后看此表的定义, 如果有分片规则,
则获取到 SQL 里分片字段的值,并匹配分片函数,得到该 SQL 对应的分片列表,然后将 SQL 发往这些分片
去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端。以 select * from Orders where prov=?
语句为例,查到 prov=wuhan,按照分片函数,wuhan 返回 dn1,于是 SQL 就发给了 MySQL1,去取 DB1 上
的查询结果,并返回给用户。
如果上述 SQL 改为 select * from Orders where prov in ( ‘wuhan’ , ‘beijing’ ), 那么, SQL 就会发给 MySQL1
与 MySQL2 去执行,然后结果集合并后输出给用户。但通常业务中我们的 SQL 会有 Order By 以及 Limit 翻页
语法,此时就涉及到结果集在 Mycat 端的二次处理,这部分的代码也比较复杂,而最复杂的则属两个表的
Jion 问题,为此,Mycat 提出了创新性的 ER 分片、全局表、HBT(Human Brain Tech)人工智能的 Catlet、以
及结合 Storm/Spark 引擎等十八般武艺的解决办法,从而成为目前业界最强大的方案,这就是开源的力量!