作者:微信小助手
发布时间:2022-06-23T00:17:06
| 软件 | 版本 |
|---|---|
| Rancher | 2.6.4 |
| Kubernetes | 1.22.7+rke2r2 |

概 述
-
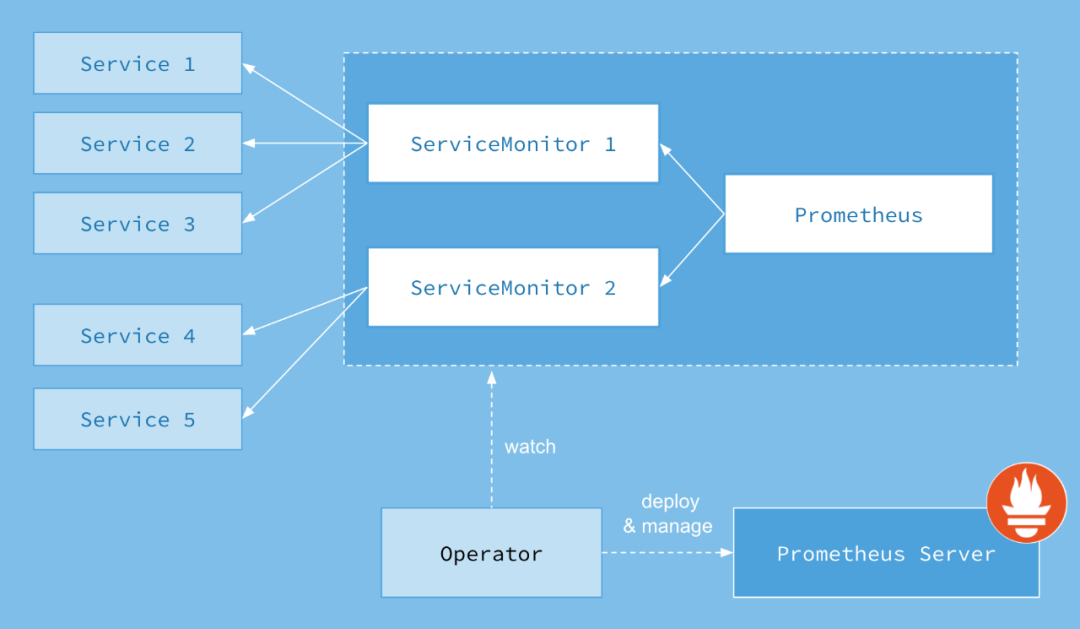
PrometheusRules:定义告警规则 -
Alert Managers:Altermanager 启动 CRD,用于 Altermanager 启动副本 -
Receivers:配置告警接收媒介 CRD -
Routers:将告警规则和告警媒介进行匹配 -
ServiceMonitor:定义 Prometheus 采集的监控指标地址 -
Pod Monitor:更细粒化的对 POD 进行监控
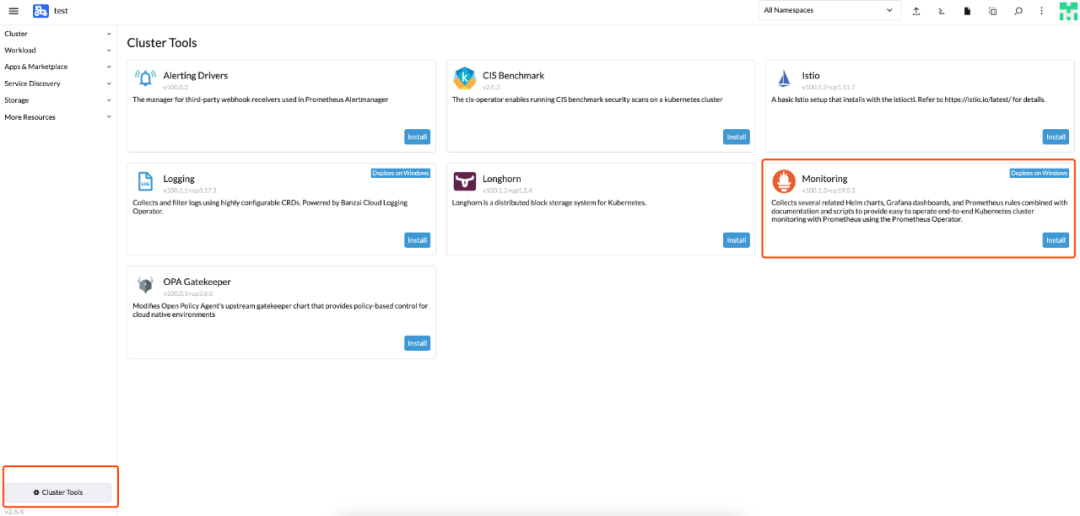
配置使用
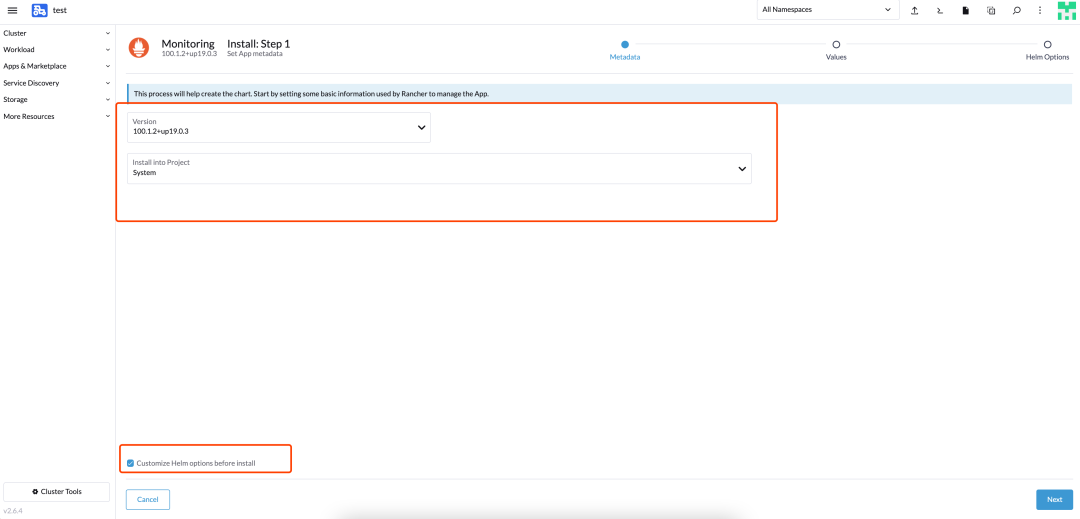
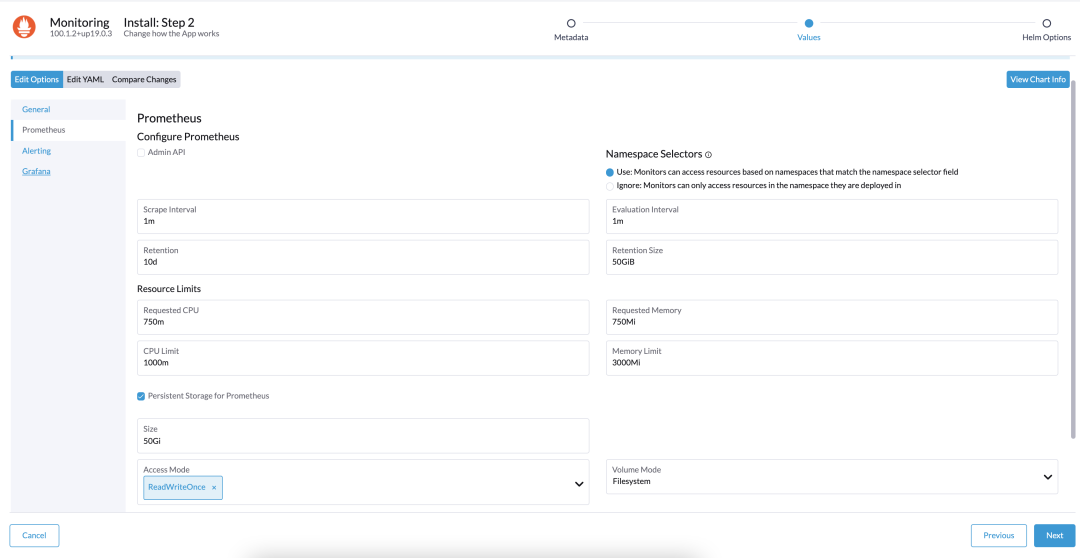
启用监控
remoteRead:- url: http://192.168.0.7:8086/api/v1/prom/read?db=prometheusremoteWrite:- url: http://192.168.0.7:8086/api/v1/prom/write?db=prometheus
podLabels:jobLabel: node-exporterresources:limits:cpu: 200mmemory: 150Mirequests:cpu: 100mmemory: 30Mi