作者:微信小助手
发布时间:2019-05-30T19:53:06
点击上方蓝字即可关注我,如果觉得我的文章不错的话,建议将该公众号置顶/星标(点击作者蓝字然后点击右上角),有惊喜哦!
主要内容
redis 简介
为什么要用 redis /为什么要用缓存
为什么要用 redis 而不用 map/guava 做缓存?
redis 和 memcached 的区别
redis 常见数据结构以及使用场景分析
redis 设置过期时间
redis 内存淘汰机制
redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)
redis 事务
缓存雪崩和缓存穿透问题解决方案
如何解决 Redis 的并发竞争 Key 问题
如何保证缓存与数据库双写时的数据一致性?
redis 简介
简单来说 redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以存写速度非常快,因此 redis 被广泛应用于缓存方向。另外,redis 也经常用来做分布式锁。redis 提供了多种数据类型来支持不同的业务场景。除此之外,redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
为什么要用 redis /为什么要用缓存
主要从“高性能”和“高并发”这两点来看待这个问题。
高性能:
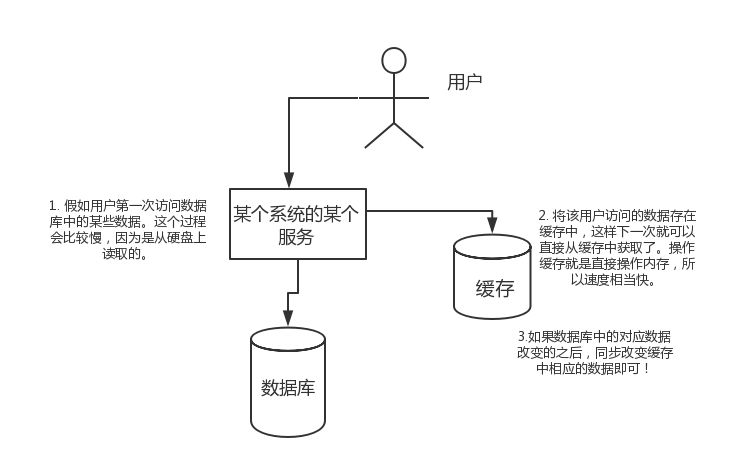
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
高并发:
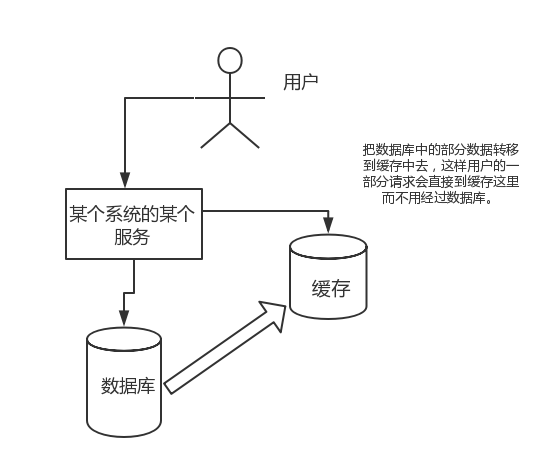
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
为什么要用 redis 而不用 map/guava 做缓存?
下面的内容来自 segmentfault 一位网友的提问,地址:https://segmentfault.com/q/1010000009106416
缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
redis 和 memcached 的区别
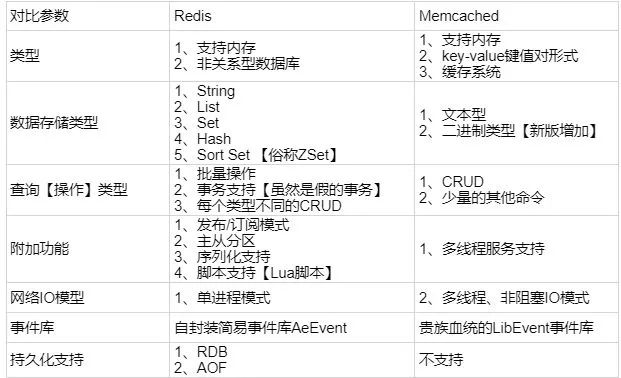
对于 redis 和 memcached 我总结了下面四点。现在公司一般都是用 redis 来实现缓存,而且 redis 自身也越来越强大了!
redis支持更丰富的数据类型(支持更复杂的应用场景):Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中。
集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 redis 目前是原生支持 cluster 模式的.
Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路 IO 复用模型。
来自网络上的一张图,这里分享给大家!
redis 常见数据结构以及使用场景分析
1. String
常用命令: set,get,decr,incr,mget 等。
String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。 常规key-value缓存应用; 常规计数:微博数,粉丝数等。
2.Hash
常用命令: hget,hset,hgetall 等。
Hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以Hash数据结构来存储用户信息,商品信息等等。比如下面我就用 hash 类型