作者:微信小助手
发布时间:2019-10-18T18:28:37

分布式事务
高可用是指系统无中断的执行功能的能力,代表了系统的可用程度,是进行系统设计时必须要遵守的准则之一。
而高可用的实现方案,无外乎就是冗余,就存储的高可用而言,问题不在于如何进行数据备份,而在于如何规避数据不一致对业务造成的影响。
对于分布式系统而言,要保证分布式系统中的数据一致性就需要一种方案,可以保证数据在子系统中始终保持一致,避免业务出现问题。
这种实现方案就叫做分布式事务,要么一起成功,要么一起失败,必须是一个整体性的事务。
理论基础
在讲解具体方案之前,有必要了解一下分布式中数据设计需要遵循的理论基础,CAP 理论和 BASE 理论,为后面的实践铺平道路。
CAP 理论
CAP,Consistency Availability Partition tolerance 的简写:
Consistency:一致性,对某个客户端来说,读操作能够返回最新的写操作结果。
Availability:可用性,非故障节点在合理的时间内返回合理的响应。
Partition tolerance:分区容错性,当出现网络分区后,系统能够继续提供服务,你知道什么是网络分区吗?
CP 架构
AP 架构
①CP 架构
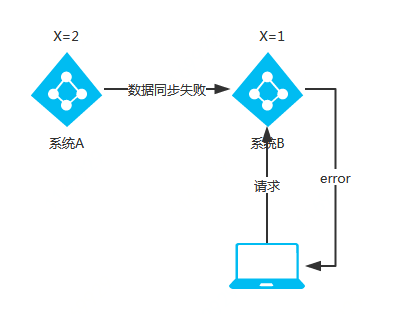
当没有出网络分区时,系统 A 与系统 B 的数据一致,X=1。
将系统 A 的 X 修改为 2,X=2。
当出现网络分区后,系统 A 与系统 B 之间的数据同步数据失败,系统 B 的 X=1。
当客户端请求系统 B 时,为了保证一致性,此时系统 B 应拒绝服务请求,返回错误码或错误信息。
②AP 架构
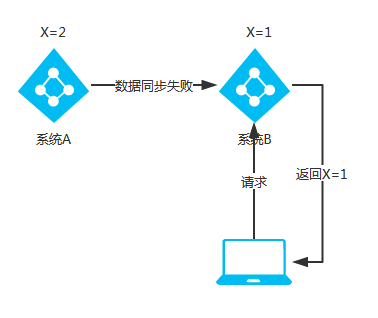
当没有出网络分区时,系统 A 与系统 B 的数据一致,X=1。
将系统 A 的 X 修改为 2,X=2。
当出现网络分区后,系统 A 与系统 B 之间的数据同步数据失败,系统 B 的 X=1。
当客户端请求系统 B 时,为了保证可用性,此时系统 B 应返回旧值,X=1。
BASE 理论
BA:Basically Available 基本可用,分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
S:Soft State 软状态,允许系统�