作者:微信小助手
发布时间:2019-10-14T18:59:09

图片来自 Pexels
由于数据库的缓存一般是针对查询的内容,而且粒度也比较小,一般只有表中的数据没有发生变动的时候,数据库的缓存才会产生作用。
但这并不能减少业务逻辑对数据库的增删改操作的 IO 压力,因此缓存技术应运而生,该技术实现了对热点数据的高速缓存,可以大大缓解后端数据库的压力。
主流应用架构
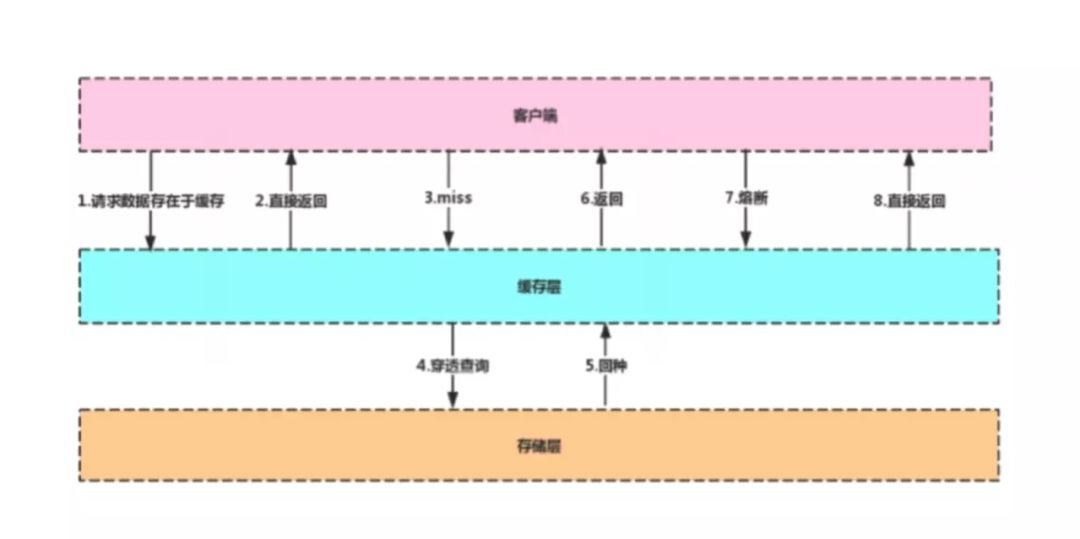
客户端在对数据库发起请求时,先到缓存层查看是否有所需的数据,如果缓存层存有客户端所需的数据,则直接从缓存层返回,否则进行穿透查询,对数据库进行查询。
如果在数据库中查询到该数据,则将该数据回写到缓存层,以便下次客户端再次查询能够直接从缓存层获取数据。
缓存中间件 Memcache 和 Redis 的区别
Memcache 的代码层类似 Hash,特点如下:
支持简单数据类型
不支持数据持久化存储
不支持主从
不支持分片
Redis 特点如下:
数据类型丰富
支持数据磁盘持久化存储
支持主从
支持分片
为什么 Redis 能这么快
Redis 完全基于内存,绝大部分请求是纯粹的内存操作,执行效率高。
Redis 使用单进程单线程模型的(K,V)数据库,将数据存储在内存中,存取均不会受到硬盘 IO 的限制,因此其执行速度极快。
另外单线程也能处理高并发请求,还可以避免频繁上下文切换和锁的竞争,如果想要多核运行也可以启动多个实例。
数据结构简单,对数据操作也简单,Redis 不使用表,不会强制用户对各个关系进行关联,不会有复杂的关系限制,其存储结构就是键值对,类似于 HashMap,HashMap 最大的优点就是存取的时间复杂度为 O(1)。
Redis 使用多路 I/O 复用模型,为非阻塞 IO。
因地制宜,优先选择时间复杂度为 O(1) 的 I/O 多路复用函数作为底层实现。
由于 Select 要遍历每一个 IO,所以其时间复杂度为 O(n),通常被作为保底方案。
基于 React 设计模式监听 I/O 事件。
Redis 的数据类型
String
最基本的数据类型,其值最大可存储 512M,二进制安全(Redis 的 String 可以包含任何二进制数据,包含 jpg 对象等)。
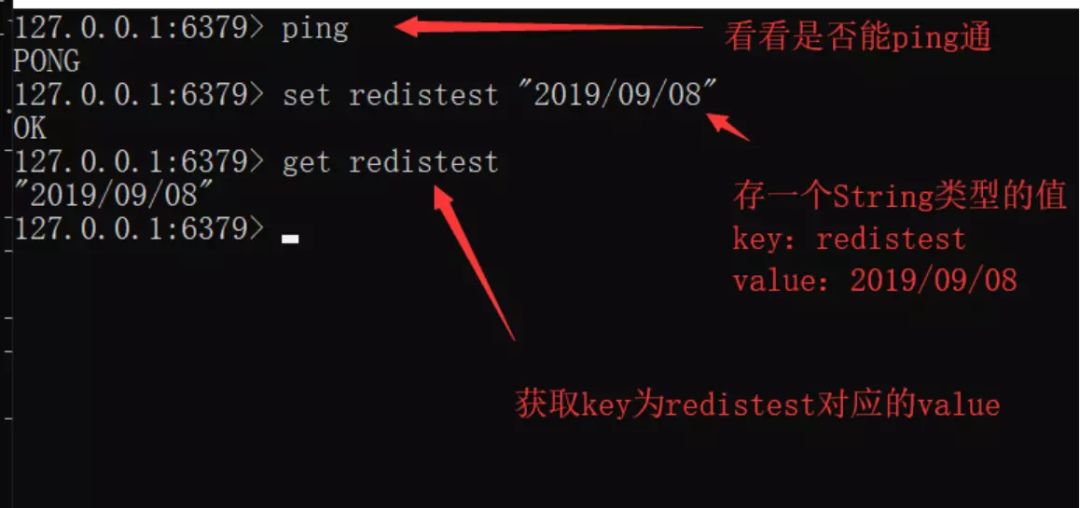
注:如果重复写入 key 相同的键值对,后写入的会将之前写入的覆盖。
Hash
String 元素组成的字典,适用于存储对象。

List
列表,按照 String 元素插入顺序排序。其顺序为后进先出。由于其具有栈的特性,所以可以实现如“最新消息排行榜”这类的功能。

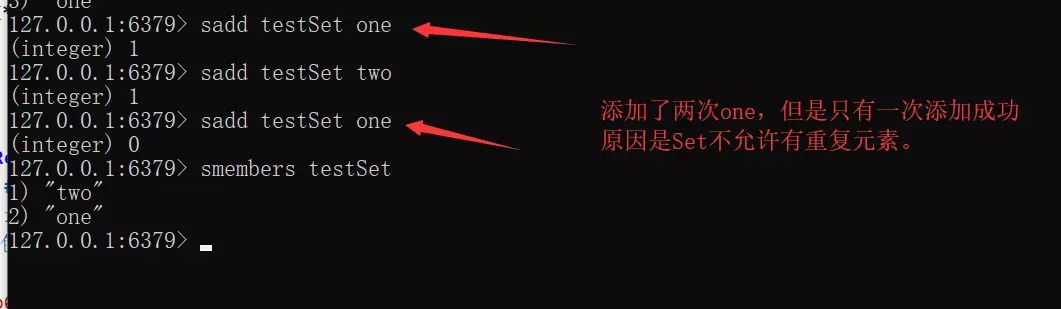
Set
String 元素组成的无序集合,通过哈希表实现(增删改查时间复杂度为 O(1)),不允许重复。
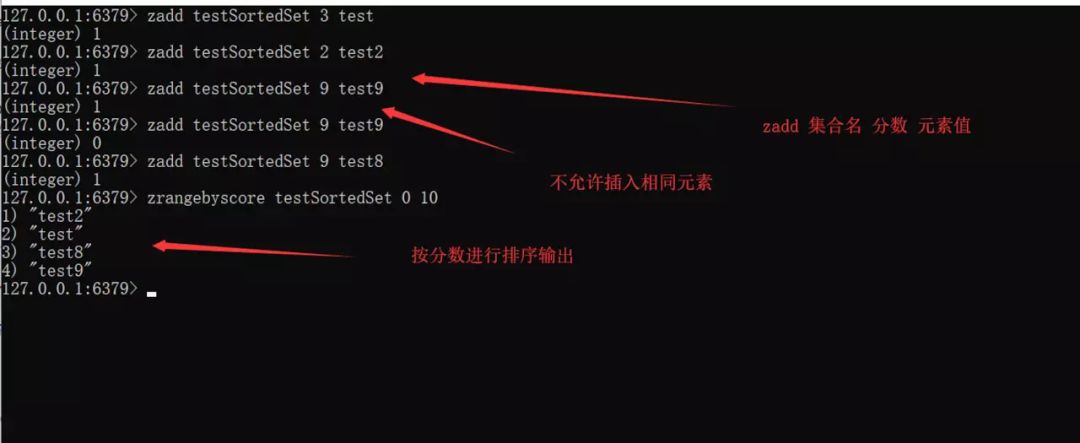
Sorted Set
通过分数来为集合中的成员进行从小到大的排序。
更高级的 Redis 类型
从海量 Key 里查询出某一个固定前缀的 Key
假设 Redis 中有十亿条 Key,如何从这么多 Key 中找到固定前缀的 Key?
keys test* //返回所有以test为前缀的key
注:
cursor:游标
MATCH pattern:查询 Key 的条件
Count:返回的条数
例:
SCAN 0 MATCH test* COUNT 10 //每次返回10条以test为前缀的key
如何通过 Redis 实现分布式锁
分布式锁
互斥性:任意时刻只有一个客户端获取到锁,不能有两个客户端同时获取到锁。
安全性:锁只能被持有该锁的客户端删除,不能由其他客户端删除。
死锁:获取锁的客户端因为某些原因而宕机继而无法释放锁,其他客户端再也无法获取锁而导致死锁,此时需要有特殊机制来避免死锁。
容错:当各个节点,如某个 Redis 节点宕机的时候,客户端仍然能够获取锁或释放锁。
如何使用 Redis 实现分布式锁
使用 SETNX 实现,SETNX key value:如果 Key 不存在,则创建并赋值。
该命令时间复杂度为 O(1),如果设置成功,则返回 1,否则返回 0。

用法:
EXPIRE key seconds

程序:
RedisService redisService = SpringUtils.getBean(RedisService.class);
long status = redisService.setnx(key,"1");
if(status == 1){
redisService.expire(key,expire);
doOcuppiedWork();
}
EX second:设置键的过期时间为 Second 秒。
PX millisecond:设置键的过期时间为 MilliSecond 毫秒。
NX:只在键不存在时,才对键进行设置操作。
XX:只在键已经存在时,才对键进行设置操作。
SET KEY value [EX seconds] [PX milliseconds] [NX|XX]
有了 SET 我们就可以在程序中使用类似下面的代码实现分布式锁了:
RedisService redisService = SpringUtils.getBean(RedisService.class);
String result = redisService.set(lockKey,requestId,SET_IF_NOT_EXIST,SET_WITH_EXPIRE_TIME,expireTime);
if("OK.equals(result)"){
doOcuppiredWork();
}
如何实现异步队列
①使用 Redis 中的 List 作为队列
使用上文所说的 Redis 的数据结构中的 List 作为队列 Rpush 生产消息,LPOP 消费消息。