作者:微信小助手
发布时间:2024-05-16T20:13:28
状态 |
线程是否活跃? |
状态的含义 |
是否占用 CPU 资源? |
|---|---|---|---|
|
|
|
刚刚创建的线程处于新建状态 |
No |
|
RUNNABLE |
|
线程已经准备好运行,等待被调度或正在执行中 |
Probably
|
|
|
线程等待获得某个监视器,该监视器锁正被另一个线程持有 |
No |
|
|
|
线程正在等待另一个线程完成某个操作 |
||
|
|
线程正在等待另一个线程在指定的时间内完成某个操作 |
||
|
|
|
线程已完成运行 |
No |
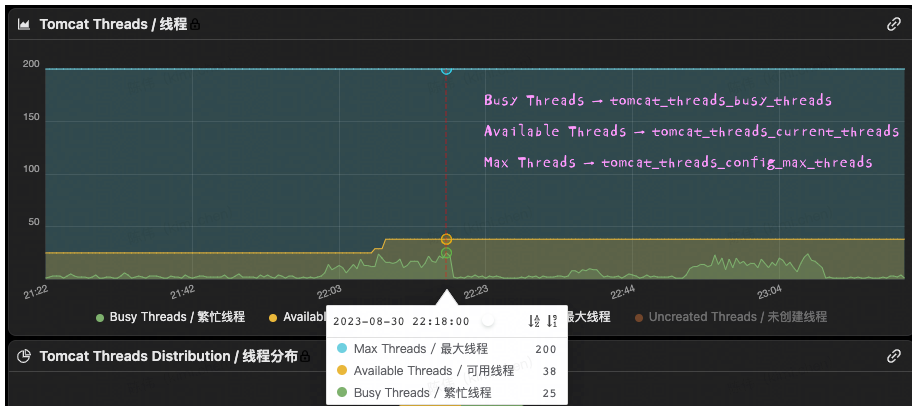
其中有3种状态表示 “等待”,分别是BLOCKED、WAITING和TIMED_WAITING。如图2:
-
WAITING和TIMED_WAITING状态表达的是线程 主动让出 CPU 时间片,等另一个线程完成某个操作后通知自己 ,再继续执行后续的逻辑。TIMED_WAITING仅仅是比WAITING多指定了一个超时时间; -
而 BLOCKED 状态则是竞争监视器锁失败,被锁 “阻挡”, 被迫等待; 
图2:Java Thread Lifecycle
让我们带着这些知识,再来翻阅 bme-trade-order-svc 应用的监控。如图3,通过 Tomcat 线程池监控曲线可以看到,工作线程确实出现了飙升,发生在 15:51:00 - 15:52:30,并且大致呈现出一种 “三段式” 增长趋势。

图3:Tomcat 线程池监控
而我也很快通过 JVM 线程状态监控曲线发现了时间和趋势都与之对应的线程状态波动的证据,如图4。可以看到 也是在 15:51:00 - 15:52:30 期间,TIMED_WAITING状态的线程数呈现明显的 “三段式” 增长。
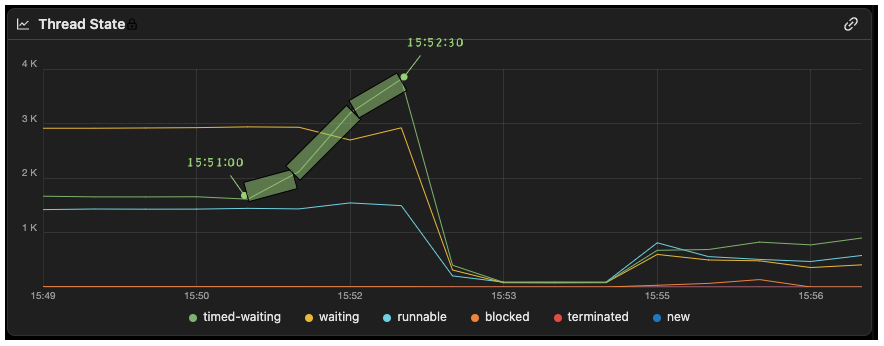
图4:JVM 线程数量(分状态)监控
这说明我之前的推论是正确的。因为某种原因,线程池中原本复用良好的工作线程纷纷主动让出 CPU,进入到TIMED_WAITING等待状态,无法再被复用。线程池只能补充新的线程来处理新的请求,可是新补充的线程也很快进入到TIMED_WAITING状态,线程池只能继续补充新线程。就这样,陷入恶性循环,最终导致线程数量飙升。
3.2 线程在等什么?
—— 等数据库连接。
对于这个问题,在实际排查的过程中,几乎可以立刻做出下意识的判断,也很容易从监控上找到证据。我们使用 HikariCP 管理数据库连接,HikariCP 有着完善的连接池指标埋点,其中部分指标的监控信息如图5。但要解释清楚细节,就没那么容易了。让我们先从理解图5中的指标开始。

图5:HikariCP 链接池监控
图中共有3条曲线,我将它们的含义归纳在了下方的表格里。
图中曲线 |
指标名 |
对应的 HikariCP 指标 |
含义 |
指标类型 |
|---|---|---|---|---|
蓝色曲线 |
Pending Connections/等待连接 |
hikaricp_pending_threads |
当前排队获取连接的线程数 |
Guage |
橙黄色曲线 |
Idle Connections/空闲连接 |
hikaricp_idle_connections |
当前空闲连接数 |
|
绿色曲线 |
Active Connections/活跃连接 |
hikaricp_active_connections |
当前正在使用的连接数 |
显然首先会关注的就是 “Pending Connections/等待连接” 指标。这个指标名起的不太好,实际上表示的是当前排队获取连接的线程数,它反映的正是线程在等待 —— 因为获取不到连接而进入了TIMED_WAITING状态。
可能有一部分本文的读者会误认为是获取到连接后,和数据库的 I/O 阻塞,导致了线程进入 TIMED_WAITING状态,但并非如此。事实上,Java 线程遇到同步 I/O 阻塞时,仍然是 RUNNABLE状态。如果你对此不是很有概念,我们可以设计一对简单的 Client - Server 实验程序来验证这一点。