作者:微信小助手
发布时间:2023-12-26T09:49:58
-
一. 索引介绍 -
二. 索引分类 -
三. 性能分析 -
四. 查询优化
一. 索引介绍
1.1 什么是Mysql索引
-
MySQL官方对于索引的定义:索引是帮助MySQL高效获取数据的数据结构。 -
MySQL在存储数据之外,数据库系统中还维护着满足特定查找算法的数据结构,这些数据结构以某种引用(指向)表中的数据,这样我们就可以通过数据结构上实现的高级查找算法来快速找到我们想要的数据。而这种数据结构就是索引。 -
简单理解为“排好序的可以快速查找数据的数据结构”。
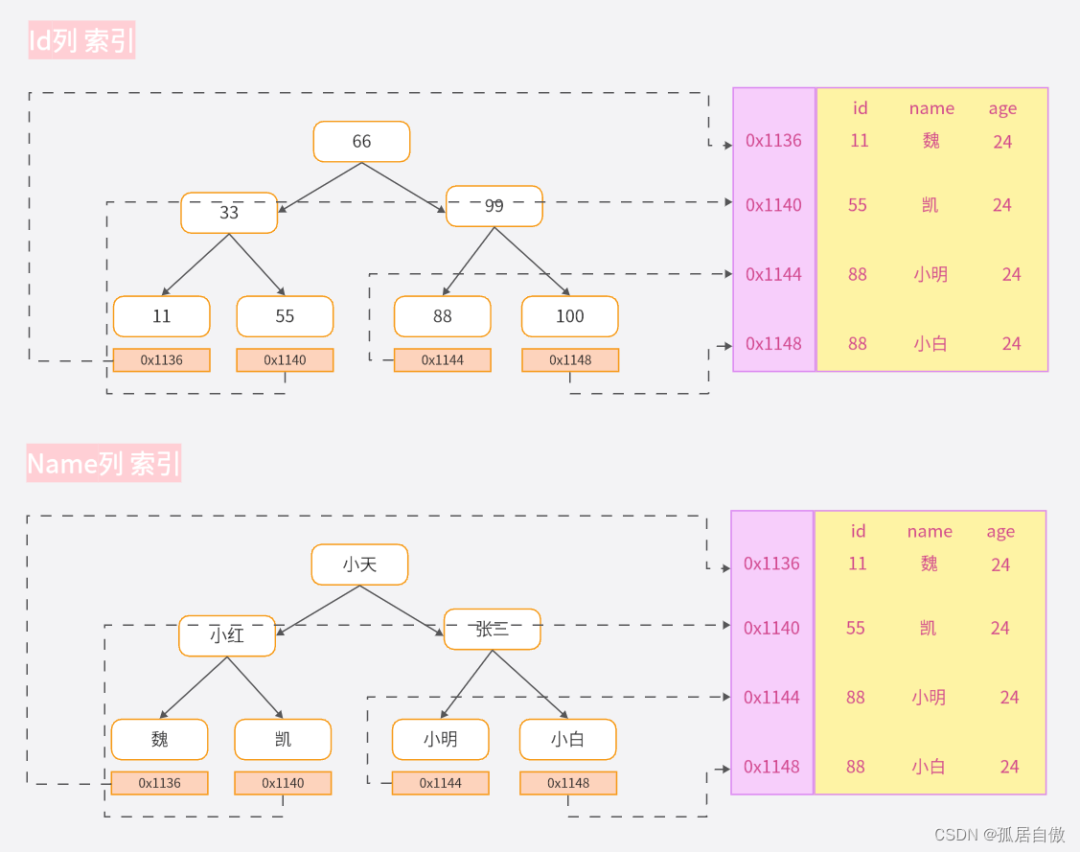
1.2 索引数据结构
下图是二叉树的索引方式:
-
二叉树数据结构的弊端:当极端情况下,数据递增插入时,会一直向右插入,形成链表,查询效率会降低。 -
MySQL中常用的的索引数据结构有BTree索引(Myisam普通索引),B+Tree索引(Innodb普通索引),Hash索引(memory存储引擎)等等。
1.3 索引优势
-
提高数据检索的效率,降低数据库的IO成本。 -
通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
1.4 索引劣势
-
索引实际上也是一张表,保存了主键和索引的字段,并且指向实体表的记录,所以索引也是需要占用空间的。 -
在索引大大提高查询速度的同时,却会降低表的更新速度,在对表进行数据增删改的同时,MySQL不仅要更新数据,还需要保存一下索引文件。 -
每次更新添加了的索引列的字段,都会去调整因为更新带来的减值变化后的索引的信息。
1.5 索引使用场景
哪些情况需要创建索引:
-
主键自动建立唯一索引 -
频繁作为查询条件的字段应该创建索引(where 后面的语句) -
查询中与其它表关联的字段,外键关系建立索引 -