作者:微信小助手
发布时间:2022-05-27T20:32:40
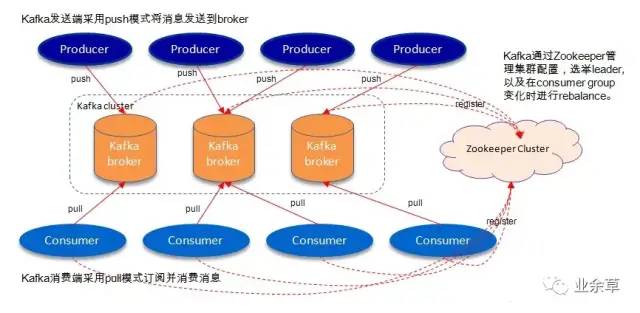
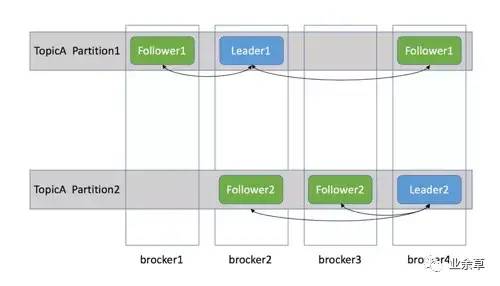
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合、异步消息、流量削锋等问题。它可以实现高性能、高可用、可伸缩和最终一致性架构,是大型分布式系统不可缺少的中间件。 消息队列在电商系统、消息通讯、日志收集等应用中扮演着关键作用,以阿里为例,其研发的消息队列(RocketMQ)在历次天猫 “双十一” 活动中支撑了万亿级的数据洪峰,为大规模交易提供了有力保障。 作为提升应用性能的重要手段,分布式消息队列技术在互联网领域得到了越来越广泛的关注 。本文将介绍四种常用的分布式消息队列开源软件: 文章目录如下: 在分布式消息队列的江湖里,Kafka 凭借其优秀的性能占据重要一席。它最初由 LinkedIn 公司开发,Linkedin 于 2010 年贡献给了 Apache基金会,之后成为顶级开源项目。 关于 Kafka,网上有很多介绍,经过不断地复制、洗稿、演绎后,难免背离原意,因此,我们还是来看一下官网给出的定义: Apache Kafka is a distributed streaming platform. Kafka 作为流平台具有以下三种能力: Kafka 适用于两类应用: kafka 包含四种核心 API。 作为一种高吞吐量的分布式发布订阅消息系统,Kafka 具有如下特性: 操作系统 环境要求 如上图所示,一个典型的 Kafka 体系架构包括若干 Producer(消息生产者),若干 Broker(Kafka 支持水平扩展,一般 Broker 数量越多,集群吞吐率越高),若干 Consumer(Group),以及一个 Zookeeper 集群。Kafka 通过 Zookeeper 管理集群配置,选举 Leader,以及在 Consumer Group 发生变化时进行 Rebalance。Producer 使用 Push(推)模式将消息发布到 Broker,Consumer 使用 Pull(拉)模式从 Broker 订阅并消费消息。 各个名词的解释请见下表: Kafka 高可用性的保障来源于其健壮的副本(Replication)策略。为了提高吞吐能力,Kafka 中每一个 Topic 分为若干 Partitions;为了保证可用性,每一个 Partition 又设置若干副本(Replicas);为了保障数据的一致性,Zookeeper 机制得以引入。基于 Zookeeper,Kafka 为每一个 Partition 找一个节点作为 Leader,其余备份作为 Follower,只有 Leader 才能处理客户端请求,而 Follower 仅作为副本同步 Leader 的数据,如下示意图:TopicA 分为两个 Partition,每个 Partition 配置两个副本。 基于上图的架构,当 Producer Push 的消息写入 Partition(分区) 时,Leader 所在的 Broker(Kafka 节点)会将消息写入自己的分区,同时还会将此消息复制到各个 Follower,实现同步。如果某个 Follower 挂掉,Leader 会再找一个替代并同步消息;如果 Leader 挂了,将会从 Follower 中选举出一个新的 Leader 替代,继续业务,这些都是由 ZooKeeper 完成的。 优点主要包括以下几点: 缺点主要有: ActiveMQ 是 Apache 下的一个子项目。之所以把它放在第二位介绍,是因为它官网上的说明: Apache ActiveMQ is the most popular and powerful open source messaging and Integration Patterns server. 居然没有“之一”,不太谦虚呀,放在第二位,以示“诫勉”。 ActiveMQ 由 Apache 出品,据官网介绍,它是最流行和最强大的开源消息总线。ActiveMQ 是一个完全支持 JMS1.1 和 J2EE 1.4 规范的 JMS Provider 实现,非常快速,支持多种语言的客户端和协议,而且可以非常容易地嵌入到企业的应用环境中,并有许多高级功能。 ActiveMQ 基于 Java 语言开发,目前最新版本为 5.1.5.6。 ActiveMQ 的特点,官网在 Features 一栏中做了非常详细的说明,我做了下翻译,如下: 相较于 Kafka,ActiveMQ 的部署简单很多,支持多个版本的 Windows 和 Unix 系统,此外,ActiveMQ 由 Java 语言开发而成,因此需要 JRE 支持。 硬件要求: 操作系统: 环境要求: ActiveMQ 的主体架构如下图所示。 默认配置下的 ActiveMQ 只适合学习而不适用于实际生产环境,ActiveMQ 的性能需要通过配置挖掘,其性能提高包括代码级性能、规则性能、存储性能、网络性能以及多节点协同方法(集群方案),所以我们优化 ActiveMQ 的中心思路也是这样的: 在生产环境中,ActiveMQ 集群的部署方式主要有下面两种。 在生产环境中,高可用(High Availability,HA)可谓 “刚需”, ActiveMQ 的高可用性架构基于 Master/Slave 模型。ActiveMQ 总共提供了四种配置方案来配置 HA,其中 Shared Nothing Master/Slave 在 5.8 版本之后不再使用了,并在 ActiveMQ 5.9 版本中引入了基于 Zookeeper 的 Replicated LevelDB Store HA 方案。 关于几种 HA 方案的详细介绍,读者可查看官网说明,在此,我仅做简单介绍。Kafka、ActiveMQ、RabbitMQ 及 RocketMQ。
1. Kafka
Kafka简介
“
Kafka 特点
Kafka 部署环境
Kafka 架构

Kafka 高可用方案
Kafka 优缺点
2. ActiveMQ
“
ActiveMQ 简介
ActiveMQ 特点
ActiveMQ 部署环境
ActiveMQ 架构
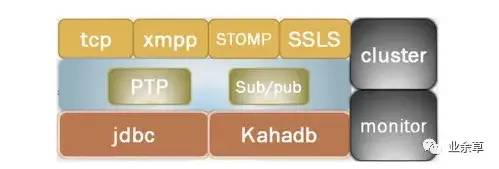
传输协议:消息之间的传递,无疑需要协议进行沟通,启动一个 ActiveMQ 便打开一个监听端口。ActiveMQ 提供了广泛的连接模式,主要包括 SSL、STOMP、XMPP。ActiveMQ 默认的使用协议为 OpenWire,端口号为 61616。通信方式:ActiveMQ 有两种通信方式,Point-to-Point Model(点对点模式),Publish/Subscribe Model (发布/订阅模式),其中在 Publich/Subscribe 模式下又有持久化订阅和非持久化订阅两种消息处理方式。消息存储:在实际应用中,重要的消息通常需要持久化到数据库或文件系统中,确保服务器崩溃时,信息不会丢失。Cluster(集群):最常见到集群方式包括 Network of Brokers 和 Master Slave。Monitor(监控):ActiveMQ 一般由 JMX 进行监控。
ActiveMQ 高可用方案
 案
案