作者:微信小助手
发布时间:2021-07-29T11:28:16
限流简介
现在说到高可用系统,都会说到高可用的保护手段:缓存、降级和限流,本博文就主要说说限流。限流是流量限速(Rate Limit)的简称,是指只允许指定的事件进入系统,超过的部分将被拒绝服务、排队或等待、降级等处理。对于server服务而言,限流为了保证一部分的请求流量可以得到正常的响应,总好过全部的请求都不能得到响应,甚至导致系统雪崩。限流与熔断经常被人弄混,博主认为它们最大的区别在于限流主要在server实现,而熔断主要在client实现,当然了,一个服务既可以充当server也可以充当client,这也是让限流与熔断同时存在一个服务中,这两个概念才容易被混淆。
那为什么需要限流呢?很多人第一反应就是服务扛不住了所以需要限流。这是不全面的说法,博主认为限流是因为资源的稀缺或出于安全防范的目的,采取的自我保护的措施。限流可以保证使用有限的资源提供最大化的服务能力,按照预期流量提供服务,超过的部分将会拒绝服务、排队或等待、降级等处理。关注公众号‘码猿技术专栏’,回复关键词‘9527’获取Spring Cloud Alibaba实战视频教程!
现在的系统对限流的支持各有不同,但是存在一些标准。在HTTP RFC 6585标准中规定了『429 Too Many Requests 』,429状态码表示用户在给定时间内发送了太多的请求,需要进行限流(“速率限制”),同时包含一个 Retry-After 响应头用于告诉客户端多长时间后可以再次请求服务.
HTTP/1.1 429 Too Many Requests
Content-Type: text/html
Retry-After: 3600
<title>Too Many Requests</title>
<h1>Too Many Requests</h1>
<p>I only allow 50 requests per hour to this Web site per
logged in user. Try again soon.</p>
很多应用框架同样集成了,限流功能并且在返回的Header中给出明确的限流标识。
-
X-Rate-Limit-Limit:同一个时间段所允许的请求的最大数目; -
X-Rate-Limit-Remaining:在当前时间段内剩余的请求的数量; -
X-Rate-Limit-Reset:为了得到最大请求数所等待的秒数。
这是通过响应头告诉调用方服务端的限流频次是怎样的,保证后端的接口访问上限,客户端也可以根据响应的Header调整请求。
限流分类
限流,拆分来看,就两个字限和流,限就是动词限制,很好理解。但是流在不同的场景之下就是不同资源或指标,多样性就在流中体现。在网络流量中可以是字节流,在数据库中可以是TPS,在API中可以是QPS亦可以是并发请求数,在商品中还可以是库存数... ...但是不管是哪一种『流』,这个流必须可以被量化,可以被度量,可以被观察到、可以统计出来。我们把限流的分类基于不同的方式分为不同的类别,如下图。

因为篇幅有限,本文只会挑选几个常见的类型分类进行说明。
限流粒度分类
根据限流的粒度分类:
-
单机限流 -
分布式限流
现状的系统基本上都是分布式架构,单机的模式已经很少了,这里说的单机限流更加准确一点的说法是单服务节点限流。单机限流是指请求进入到某一个服务节点后超过了限流阈值,服务节点采取了一种限流保护措施。关注公众号‘码猿技术专栏’,回复关键词‘9527’获取Spring Cloud Alibaba实战视频教程!
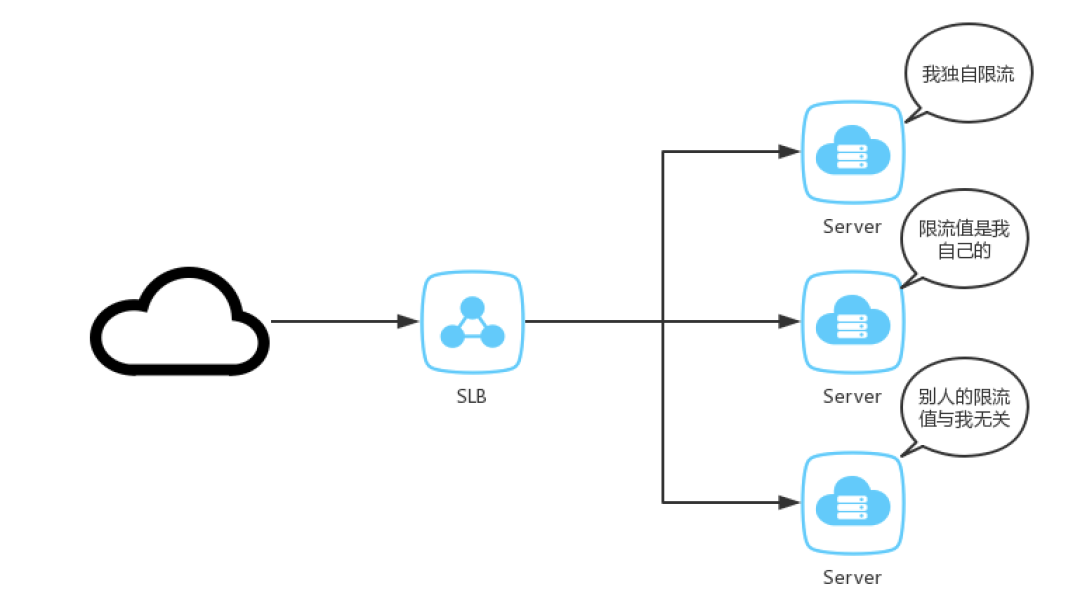
分布式限流狭义的说法是在接入层实现多节点合并限流,比如NGINX+redis,分布式网关等,广义的分布式限流是多个节点(可以为不同服务节点)有机整合,形成整体的限流服务。
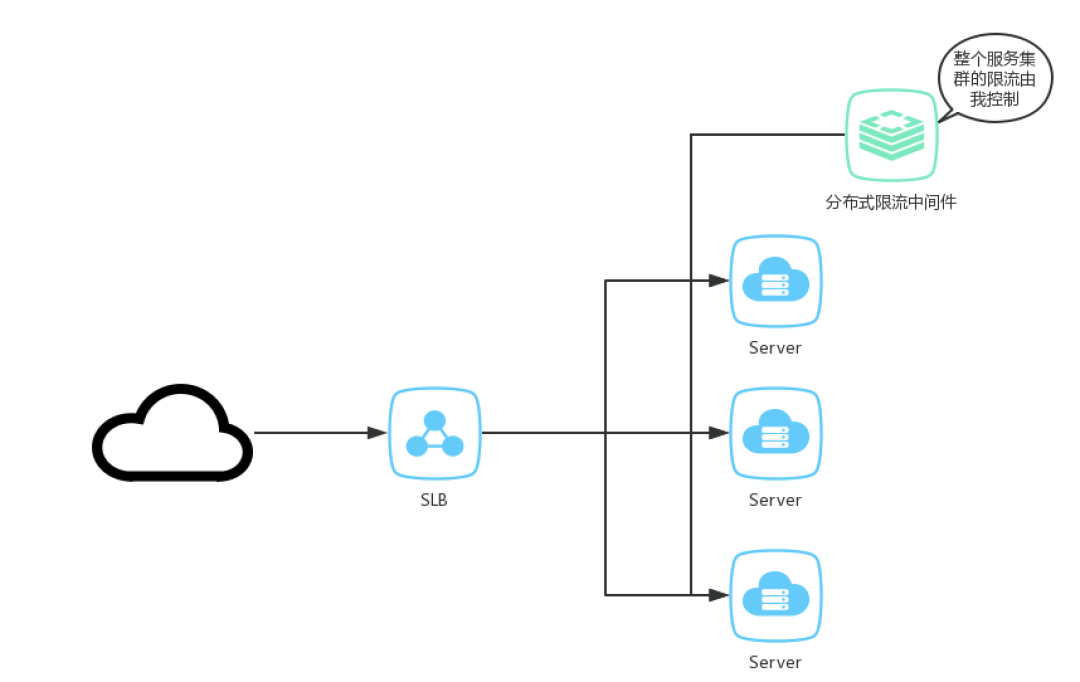
单机限流防止流量压垮服务节点,缺乏对整体流量的感知。分布式限流适合做细粒度不同的限流控制,可以根据场景不同匹配不同的限流规则。与单机限流最大的区别,分布式限流需要中心化存储,常见的使用redis实现。引入了中心化存储,就需要解决以下问题:
-
数据一致性
在限流模式中理想的模式为时间点一致性。时间点一致性的定义中要求所有数据组件的数据在任意时刻都是完全一致的,但是一般来说信息传播的速度最大是光速,其实并不能达到任意时刻一致,总有一定的时间不一致,对于我们CAP中的一致性来说只要达到读取到最新数据即可,达到这种情况并不需要严格的任意时间一致。这只能是理论当中的一致性模型,可以在限流中达到线性一致性即可。
-
时间一致性
这里的时间一致性与上述的时间点一致性不一样,这里就是指各个服务节点的时间一致性。一个集群有3台机器,但是在某一个A/B机器的时间为
Tue Dec 3 16:29:28 CST 2019,C为Tue Dec 3 16:29:28 CST 2019,那么它们的时间就不一致。那么使用ntpdate进行同步也会存在一定的误差,对于时间窗口敏感的算法就是误差点。 -
超时
在分布式系统中就需要网络进行通信,会存在网络抖动问题,或者分布式限流中间件压力过大导致响应变慢,甚至是超时时间阈值设置不合理,导致应用服务节点超时了,此时是放行流量还是拒绝流量?
-
性能与可靠性
分布式限流中间件的资源总是有限的,甚至可能是单点的(写入单点),性能存在上限。如果分布式限流中间件不可用时候如何退化为单机限流模式也是一个很好的降级方案。
限流对象类型分类
按照对象类型分类:
-
基于请求限流 -
基于资源限流
基于请求限流,一般的实现方式有限制总量和限制QPS。限制总量就是限制某个指标的上限,比如抢购某一个商品,放量是10w,那么最多只能卖出10w件。微信的抢红包,群里发一个红包拆分为10个,那么最多只能有10人可以抢到,第十一个人打开就会显示『手慢了,红包派完了』。

限制QPS,也是我们常说的限流方式,只要在接口层级进行,某一个接口只允许1秒只能访问100次,那么它的峰值QPS只能为100。限制QPS的方式最难的点就是如何预估阈值,如何定位阈值,下文中会说到。关注公众号‘码猿技术专栏’,回复关键词‘9527’获取Spring Cloud Alibaba实战视频教程!
基于资源限流是基于服务资源的使用情况进行限制,需要定位到服务的关键资源有哪些,并对其进行限制,如限制TCP连接数、线程数、内存使用量等。限制资源更能有效地反映出服务当前地清理,但与限制QPS类似,面临着如何确认资源的阈值为多少。这个阈值需要不断地调优,不停地实践才可以得到一个较为满意地值。
限流算法分类
不论是按照什么维度,基于什么方式的分类,其限流的底层均是需要算法来实现。下面介绍实现常见的限流算法:
-
计数器 -
令牌桶算法 -
漏桶算法
计数器
固定窗口计数器
计数限流是最为简单的限流算法,日常开发中,我们说的限流很多都是说固定窗口计数限流算法,比如某一个接口或服务1s最多只能接收1000个请求,那么我们就会设置其限流为1000QPS。该算法的实现思路非常简单,维护一个固定单位时间内的计数器,如果检测到单位时间已经过去就重置计数器为零。
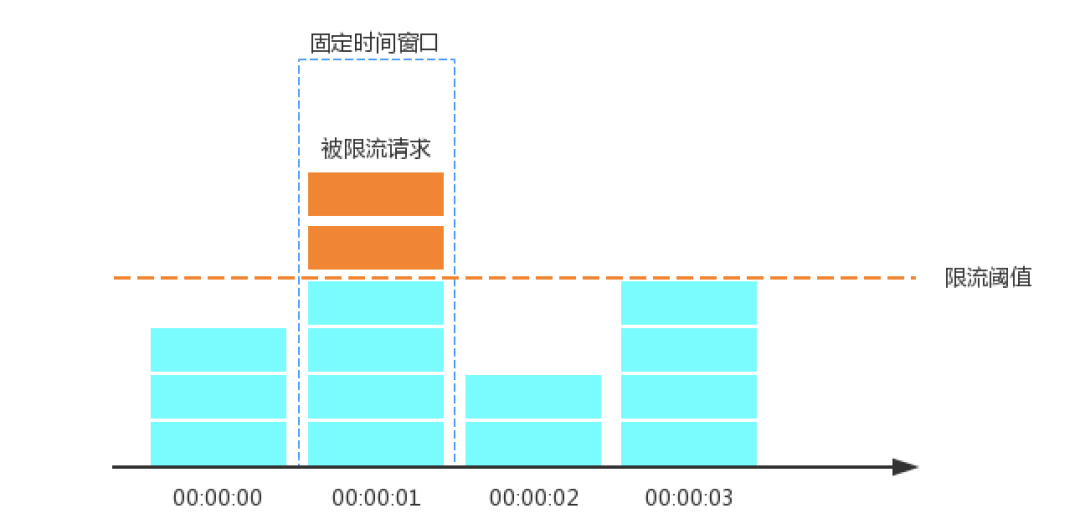
其操作步骤:
-
时间线划分为多个独立且固定大小窗口; -
落在每一个时间窗口内的请求就将计数器加1; -
如果计数器超过了限流阈值,则后续落在该窗口的请求都会被拒绝。但时间达到下一个时间窗口时,计数器会被重置为0。
下面实现一个简单的代码。
package limit
import (
"sync/atomic"
"time"
)
type Counter struct {
Count uint64 // 初始计数器
Limit uint64 // 单位时间窗口最大请求频次
Interval int64 // 单位ms
RefreshTime int64 // 时间窗口
}
func NewCounter(count, limit uint64, interval, rt int64) *Counter {
return &Counter{
Count: count,
Limit: limit,
Interval: interval,
RefreshTime: rt,
}
}
func (c *Counter) RateLimit() bool {
now := time.Now().UnixNano() / 1e6
if now < (c.RefreshTime + c.Interval) {
atomic.AddUint64(&c.Count, 1)
return c.Count <= c.Limit
} else {
c.RefreshTime = now
atomic.AddUint64(&c.Count, -c.Count)
return true
}
}
测试代码:
package limit
import (
"fmt"
"testing"
"time"
)
func Test_Counter(t *testing.T) {
counter := NewCounter(0, 5, 100, time.Now().Unix())
for i := 0; i < 10; i++ {
go func(i int) {
for k := 0; k <= 10; k++ {
fmt.Println(counter.RateLimit())
if k%3 == 0 {
time.Sleep(102 * time.Millisecond)
}
}
}(i)
}
time.Sleep(10 * time.Second)
}
看了上面的逻辑,有没有觉得固定窗口计数器很简单,对,就是这么简单,这就是它的一个优点实现简单。同时也存在两个比较严重缺陷。试想一下,固定时间窗口1s限流阈值为100,但是前100ms,已经请求来了99个,那么后续的900ms只能通过一个了,就是一个缺陷,基本上没有应对突发流量的能力。第二个缺陷,在00:00:00这个时间窗口的后500ms,请求通过了100个,在00:00:01这个时间窗口的前500ms还有100个请求通过,对于服务来说相当于1秒内请求量达到了限流阈值的2倍。
滑动窗口计数器
滑动时间窗口算法是对固定时间窗口算法的一种改进,这词被大众所知实在TCP的流量控制中。固定窗口计数器可以说是滑动窗口计数器的一种特例,滑动窗口的操作步骤:
-
将单位时间划分为多个区间,一般都是均分为多个小的时间段; -
每一个区间内都有一个计数器,有一个请求落在该区间内,则该区间内的计数器就会加一; -
每过一个时间段,时间窗口就会往右滑动一格,抛弃最老的一个区间,并纳入新的一个区间; -
计算整个时间窗口内的请求总数时会累加所有的时间片段内的计数器,计数总和超过了限制数量,则本窗口内所有的请求都被丢弃。
时间窗口�