作者:微信小助手
发布时间:2020-11-27T00:17:37
在服务上线后总有些不尽人意的时候,初次使用Redis集群部署Redis主从同步出现切换故障,也是常有发生,本篇文章主要分享Redis主从同步切换有哪些坑可以尽量避免!
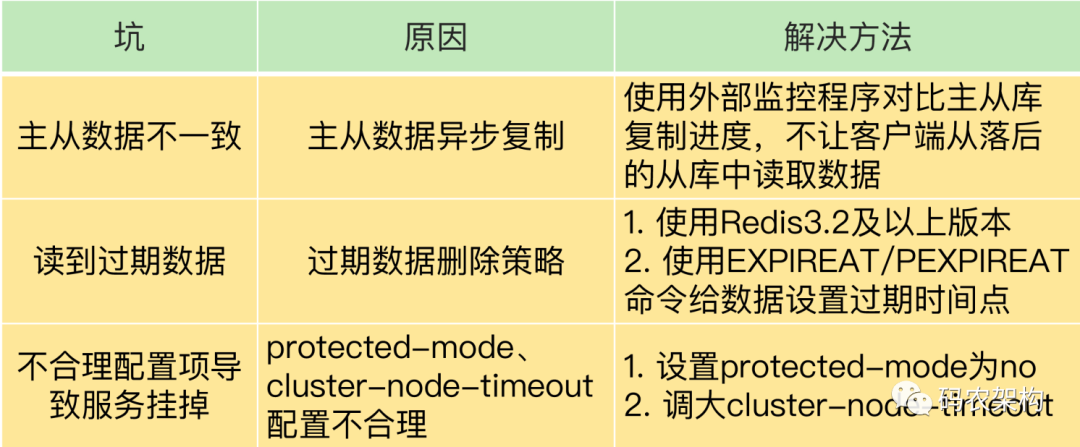
主从数据不一致
那为啥会出现这个坑呢?其实这是因为主从库间的命令复制是异步进行的。那在什么情况下,从库会滞后执行同步命令呢?
-
一方面,主从库间的网络可能会有传输延迟,所以从库不能及时地收到主库发送的命令,从库上执行同步命令的时间就会被延后。 -
另一方面,即使从库及时收到了主库的命令,但是,也可能会因为正在处理其它复杂度高的命令(例如集合操作命令)而阻塞。
两种解决方法:
-
在硬件环境配置方面,我们要尽量保证主从库间的网络连接状况良好 -
可以开发一个外部程序来监控主从库间的复制进度
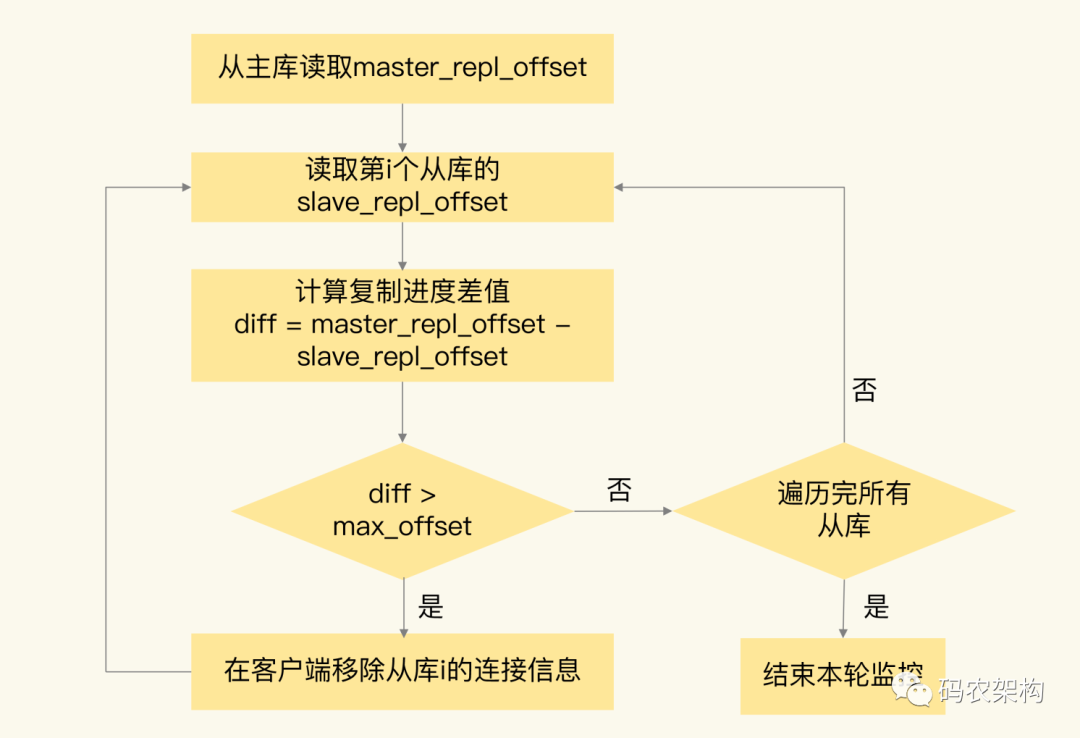
因为 Redis 的 INFO replication 命令可以查看主库接收写命令的进度信息(master_repl_offset)和从库复制写命令的进度信息(slave_repl_offset),所以,我们就可以开发一个监控程序,先用 INFO replication 命令查到主、从库的进度,然后,我们用 master_repl_offset 减去 slave_repl_offset,这样就能得到从库和主库间的复制进度差值了
读取过期数据
我们在使用 Redis 主从集群时,有时会读到过期数据。例如,数据 X 的过期时间是 202010240900,但是客户端在 202010240910 时,仍然可以从从库中读到数据 X。一个数据过期后,应该是被删除的,客户端不能再读取到该数据,但是,Redis 为什么还能在从库中读到过期的数据呢?这是由 Redis 的过期数据删除策略引起的。
-
Redis 同时使用了两种策略来删除过期的数据,分别是惰性删除策略和定期删除策略。先说惰性删除策略。当一个数据的过期时间到了以后,并不会立即删除数据,而是等到再有请求来读写这个数据时,对数据进行检查,如果发现数据已经过期了,再删除这个数据。
在访问时检查过期时间 (被动). 如果访问的是主库, 那么发现数据过期会删除, 且不返回给客户端. 但是从库的行为与版本有关: 3.2之前的不检查过期, 会返回数据, 3.2之后虽然不删除过期数据, 但是返回空值.
定期删除策略是指,Redis 每隔一段时间(默认 100ms),就会随机选出一定数量的数据,检查它们是否过期,并把其中过期的数据删除,这样就可以及时释放一些内存。
主动. 定期删除策略每次删除的过期数据不多 (避免影响性能), 所以应用可能读到未来得及删除的数据.
只要使用了 Redis 3.2 后的版本,就不会读到过期数据了吗?其实还是会的。这跟 Redis 用于设置过期时间的命令有关系,有些命令给数据设置的过期时间在从库上可能会被延后,导致应该过期的数据又在从库上被读取到了
-
EXPIRE 和 PEXPIRE:它们给数据设置的是从命令执行时开始计算的存活时间; -
EXPIREAT 和 PEXPIREAT:它们会直接把数据的过期时间设置为具体的一个时间点。
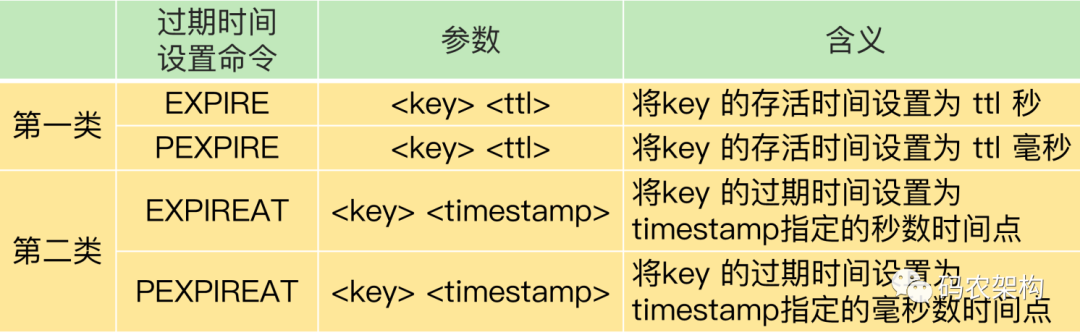
为了避免这种情况,我给你的建议是,在业务应用中使用 EXPIREAT/PEXPIREAT 命令,把数据的过期时间设置为具体的时间点,避免读到过期数据。
不合理的配置导致服务挂掉
这里涉及到的配置项有两个,分别是 protected-mode 和 cluster-node-timeout。
Protected-mode 配置项
protected-mode nobind 192.168.10.3 192.168.10.4 192.168.10.5
Cluster-node-timeout 配置项
这个配置项设置了 Redis Cluster 中实例响应心跳消息的超时时间。当我们在 Redis Cluster 集群中为每个实例配置了“一主一从”模式时,如果主实例发生故障,从实例会切换为主实例,受网络延迟和切换操作执行的影响,切换时间可能较长,就会导致实例的心跳超时(超出 cluster-node-timeout)。实例超时后,就会被 Redis Cluster 判断为异常。而 Redis Cluster 正常运行的条件就是,有半数以上的实例都能正常运行。所以,如果执行主从切换的实例超过半数,而主从切换时间又过长的话,就可能有半数以上的实例心跳超时,从而可能导致整个集群挂掉。所以,我建议你将 cluster-node-timeout 调大些(例如 10 到 20 秒)
总结
- END -
往期推荐
