作者:微信小助手
发布时间:2020-06-07T14:09:45
点击上方“五分钟学算法”,选择“星标”公众号 重磅干货,第一时间送达



1 关系型数据库与NoSQL
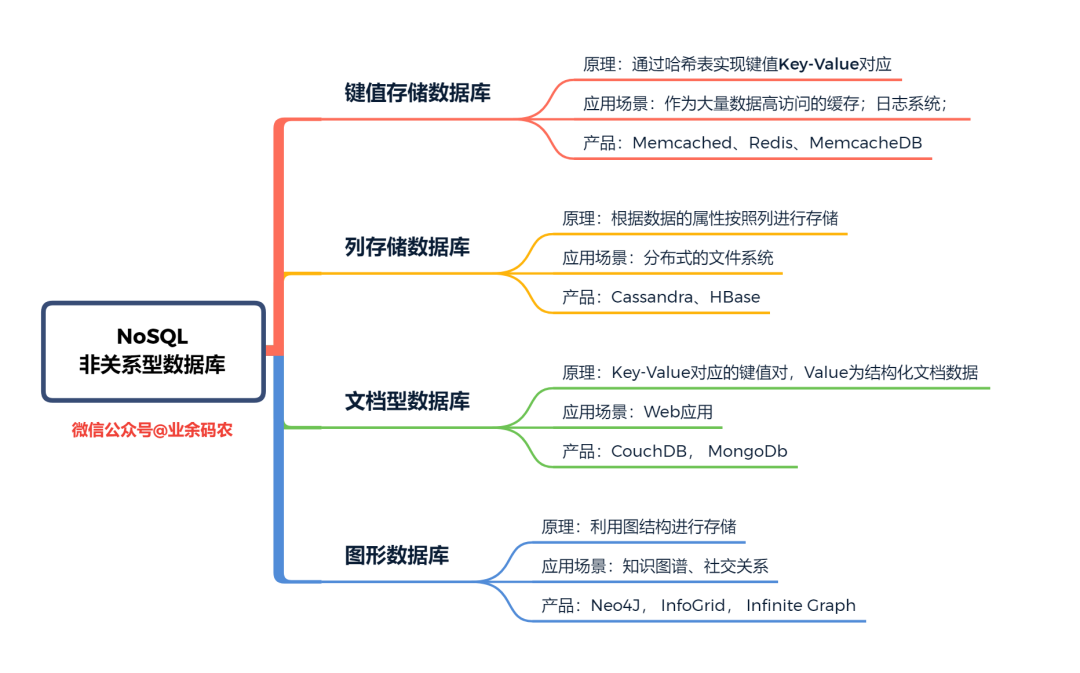
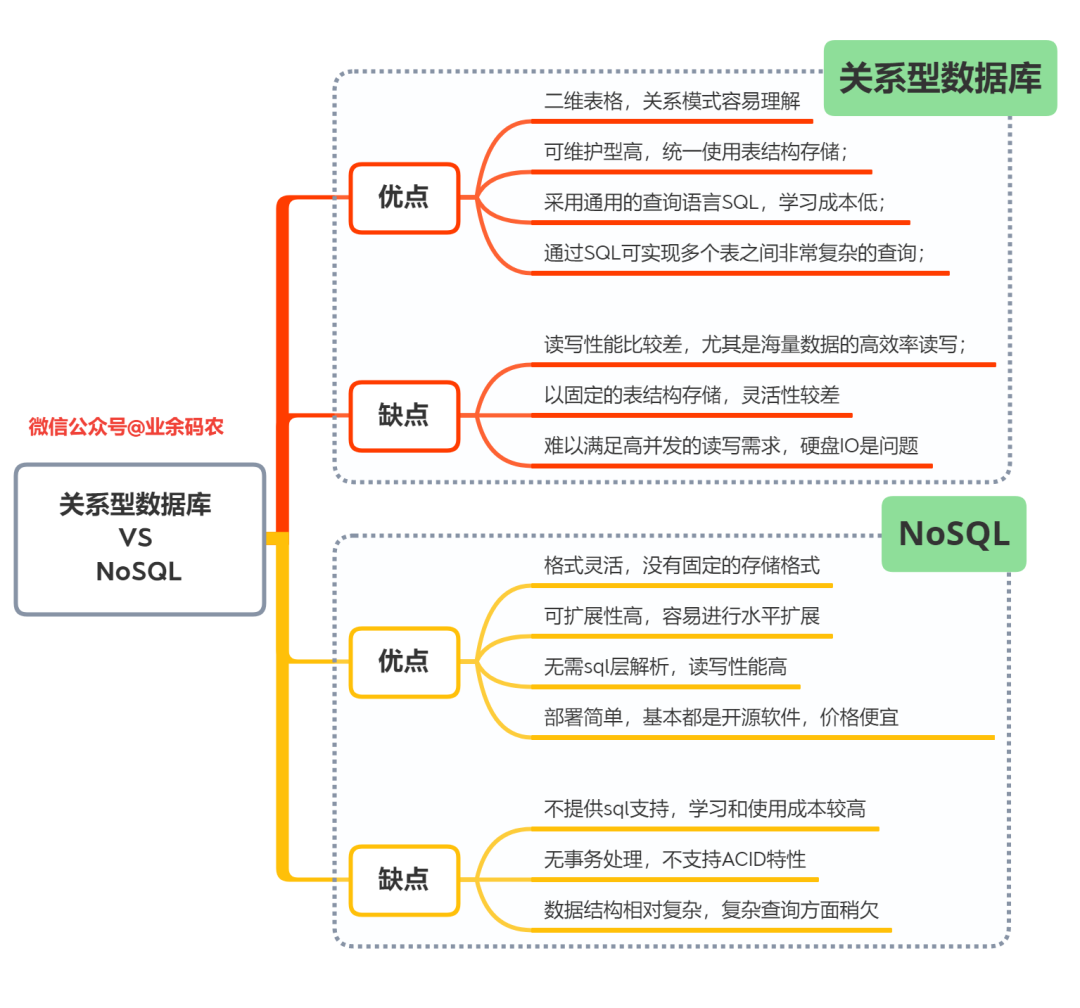 关系型数据库与NoSQL的优缺点对比
关系型数据库与NoSQL的优缺点对比
2 MySQL简介
介绍
逻辑架构

3 MySQL事务
原子性
持久性
隔离性





next-key lock
机制实现的。
next-key lock