作者:微信小助手
发布时间:2018-10-11T18:39:01

但是随着分布式的快速发展,本地的加锁往往不能满足我们的需要,在我们的分布式环境中上面加锁的方法就会失去作用。
于是人们为了在分布式环境中也能实现本地锁的效果,也是纷纷各出其招,今天让我们来聊一聊一般分布式锁实现的套路。
为何需要分布式锁
Martin Kleppmann 是英国剑桥大学的分布式系统的研究员,之前和 Redis 之父 Antirez 进行过关于 RedLock(红锁,后续有讲到)是否安全的激烈讨论。
Martin 认为一般我们使用分布式锁有两个场景:
效率:使用分布式锁可以避免不同节点重复相同的工作,这些工作会浪费资源。比如用户付了钱之后有可能不同节点会发出多封短信。
正确性:加分布式锁同样可以避免破坏正确性的发生,如果两个节点在同一条数据上面操作,比如多个节点机器对同一个订单操作不同的流程有可能会导致该笔订单最后状态出现错误,造成损失。
分布式锁的一些特点
当我们确定了在不同节点上需要分布式锁,那么我们需要了解分布式锁到底应该有哪些特点?
分布式锁的特点如下:
互斥性:和我们本地锁一样互斥性是最基本,但是分布式锁需要保证在不同节点的不同线程的互斥。
可重入性:同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。
锁超时:和本地锁一样支持锁超时,防止死锁。
高效,高可用:加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
支持阻塞和非阻塞:和 ReentrantLock 一样支持 lock 和 trylock 以及 tryLock(long timeOut)。
支持公平锁和非公平锁(可选):公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。
常见的分布式锁
我们了解了一些特点之后,我们一般实现分布式锁有以下几个方式:
MySQL
ZK
Redis
自研分布式锁:如谷歌的 Chubby。
下面分开介绍一下这些分布式锁的实现原理。
MySQL
首先来说一下 MySQL 分布式锁的实现原理,相对来说这个比较容易理解,毕竟数据库和我们开发人员在平时的开发中息息相关。
对于分布式锁我们可以创建一个锁表:
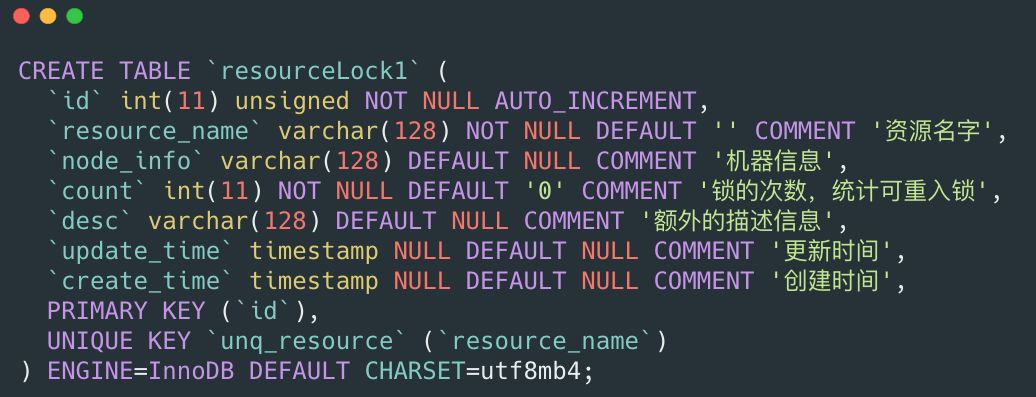
前面我们所说的 lock(),trylock(long timeout),trylock() 这几个方法可以用下面的伪代码实现。
lock()
lock 一般是阻塞式的获取锁,意思就是不获取到锁誓不罢休,那么我们可以写一个死循环来执行其操作